Convolutional Neural Network를 이용한 MNIST
# 필요 라이브러리 호출
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
import numpy as np
import matplotlib.pyplot as plt
train_dataset = datasets.MNIST('./mnist_data', # torchvision 안에 있는 MNIST dataset을 불러옴
download=True, # 다운로드 할것인가?
train=True, # train 용도 구분
transform=transforms.ToTensor() # torch를 입력 받을 수 있는 자료형태로 변환
)
test_dataset = datasets.MNIST('./mnist_data',
download=False,
train=False,
transform=transforms.ToTensor()
)
# 데이터셋 로더 호출
train_loader = torch.utils.data.DataLoader(train_dataset,batch_size=128,shuffle=True,drop_last=False)
test_loader = torch.utils.data.DataLoader(test_dataset,batch_size=128,shuffle=False,drop_last=False)
# 장치 호출
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
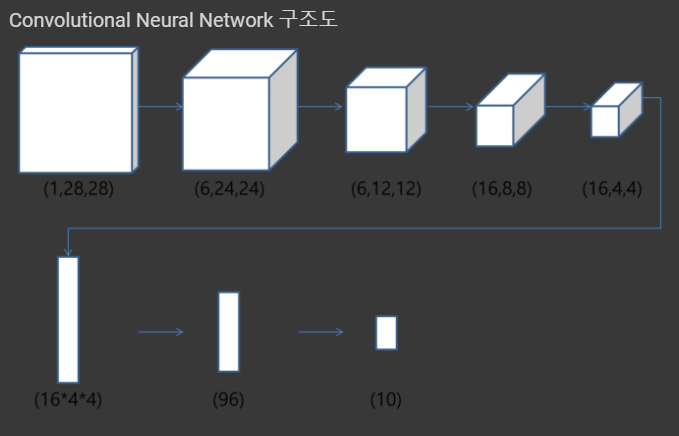
(1,28,28) 컬러 형태의 이미지가 아니라 밝고 어두움만 구분가능한 1 채널에서
Convolution neural network를 거치게 되면 채널의 영향에 의해 채널이 많아지고 가로와 세로가 줄어든다. (6, 24, 24)
그 다음 max-polling을 거쳐서 가로와 세로를 반으로 줄여준다. (6, 12, 12)
그 다음에 Convolution2d를 연산을 통해서 또 한번 사이즈 변형이 일어난다. (16, 8, 8)
채널이 6채널에서 16채널로 변함으로써 이미지의 특성을 담는 부분들이 많아졌음을 알 수 있다.
커널 연산의 영향에 의해서 가로와 세로가 줄어드는 것 또한 확인 할 수 있다.
그리고 또한번 맥스풀링을 통해서 가로와 세로를 반으로 줄여준다. (16,4,4)
여기까지 과정을 거치면 충분히 학습 되었다고 가정을 하고 Fully-connected layer로 변형시킴으로써
이 입력 이미지가 숫자 0~9 중에서 어느 숫자 레이블에 대한 확률이 높은가를 구분지어야한다.
Flatten 함수를 통해서 convolution layer의 마지막 계층인 (16,4,4)라는 이미지 차원의 텐서를 (16*4*4)라는 하나의 벡터로 만들어준다.(컨볼루션 연산에서 풀리커넥티드 단계로 변환시켜주는 단계로 변화하게됨, 그래서 더 이상 이미지 같은 차원의 텐서가 아니라 1차원 벡터로 구성된 16*4*4의 크기가 1차원의 벡터로 변화시키게됨)
그 다음 Linear 기능을 이용하여 (16*4*4)에서 96개의 로드로 변환시키고 마지막 Fully-connected layer를 이용하여
96개의 로드를 숫자 0에서부터 9까지 확률에 해당하는 10개의 로드로 변환시켜준다.
dropout의 개념 : fully connected layer에서 입력노드에서 출력노드까지 진행되는 과정중에서 일부의 20% 정도의 신경망을 사용하지않고 포워드 프로파게이션을 진행한다는 의미 드롭아웃을 진행하게 되면 오버피팅을 방지하는 효과를 가져다준다.
nn. Conv2d (in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
# Convolutional Neural Network - 모델생성
'''
입력텐서
(batch,1,28,28)
신경망구조
커널, 입력채널, 출력채널, 스트라이드, 패딩 출력텐서
Conv 5x5 1 6 1x1 0 (batch,6,24,24)
Maxpool 2x2 2x2 (batch,6,12,12)
Conv 5x5 6 16 1x1 0 (batch,16,8,8)
Maxpool 2x2 2x2 (batch,16,4,4)
Flatten (batch,16*4*4)
입력노드, 출력노드
FC 16*4*4 96 (batch,96)
dropout 20%(가중치행렬의 20%)
FC 96 10 (batch,10)
'''
class CNN_MNIST(nn.Module):
def __init__(self):
super(CNN_MNIST,self).__init__()
self.conv1 = nn.Conv2d(1,6,5,1)
self.pool1 = nn.MaxPool2d(2,2)
self.conv2 = nn.Conv2d(6,16,5,1)
self.pool2 = nn.MaxPool2d(2,2)
self.lin1 = nn.Linear(16*4*4,96) # 맥스풀링을 통해서 플래튼 되었다고 가정했을 때 Fully connected layer로 변하는 첫단계, 16*4*4개의 입력 로드에서 96개의 은닉층으로 변환
self.drop1 = nn.Dropout(0.2) # 16*4*4에서 96으로 변하는 과정에서 20% 데이터를 의도적으로 손실
self.lin2 = nn.Linear(96,10) # 96개의 로드에서 10개의 로드로 변환시킴으로써 mnist 데이터를 해석가능하게함
def forward(self,x):
# relu함수를 통해서 foward propagation을 함
# convolution neural network를 담당하는 부분 : kernel --> 학습의 대상이 됨
x = F.relu(self.conv1(x))
x = self.pool1(x)
x = F.relu(self.conv2(x))
x = self.pool2(x) # (b,16,4,4)
# Fully connected layer 부분 : weight matrix --> 학습의 대상이됨
x = x.view(x.shape[0],-1) # flatten --> (b, 16*4*4)
x = F.relu(self.drop1(self.lin1(x)))
x = F.softmax(self.lin2(x)) # nn.CrossEntropyLoss를 사용하려면 x=self.lin2(x)
return x
# 확률간 거리 Kullback-Leibler divergence
# 확률과 확률간의 거리를 좁히는 방식으로 mnist를 원핫 인코딩을 하게 되면 그 값이 확률분포라고 하는 개념이 된다.
# 그런데 우리가 추론한 확률분포와 우리가 정답이라고 알고 있었던 확률분포간의 거리를 loss함수 즉 손실함수 목적함수로 설정하게 해주면 우리가 목표로 하는 확률분포처럼 변형된다.
def kl_div(prob1,prob2):
'''
prob1: label
prob2: inference
'''
return torch.sum(prob1*torch.log(prob1/prob2+1e-15))
model = CNN_MNIST().to(device)
optimizer = optim.Adam(model.parameters(),lr=1e-04) # kernel, weight matrix --> 학습의 대상
#criterion = nn.CrossEntropyLoss()으로도 이용 가능
for ep in range(20):
model.train()
train_loss = 0
for X,Y in train_loader: # X (batch,1,28,28), Y (batch,1) --> (batch, 10)
X = X.to(device)
Y = Y.to(device)
# One-hot encoding --> criterion이용하려면 사용금지
Y_label = torch.zeros((Y.shape[0],10)).to(device)
Y_label[range(Y.shape[0]),Y]=1
Y_infer = model(X)
loss = kl_div(Y_label,Y_infer)
#loss = criterion(Y_infer,Y_label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
model.eval()
test_loss = 0
for X,Y in test_loader:
X = X.to(device)
Y = Y.to(device)
Y_label = torch.zeros((Y.shape[0],10)).to(device)
Y_label[range(Y.shape[0]),Y]=1
Y_infer = model(X)
loss = kl_div(Y_label,Y_infer)
test_loss += loss.item()
if ep % 5 == 0:
print('Episode {:d}, Train_loss {:.3f}, Test_loss {:.3f}'
.format(ep,train_loss/len(train_loader),test_loss/len(test_loader)))
model.eval()
correct = 0
for X,Y in test_loader:
X = X.to(device) # 이미지
Y = Y.to(device) # 실제 레이블
Y_infer = model(X) # 출력 레이블
correct += np.mean(torch.argmax(Y_infer,dim=1).detach().cpu().numpy()==Y.detach().cpu().numpy())
# 실제 레이블과 출력 레이블을 통해서 인공지능이 추출해낸 이미지의 번호라는 것을 비교해봤을 때 얼마나 많이 맞느냐를 카운트 해주는 부분
print("테스트 데이터 정확도: {:.4f}%"
.format(100.0*correct/len(test_loader)))
# Checking
X,Y = test_dataset[0]
X = X.to(device)
Y_infer = model(torch.unsqueeze(X,0))
print('실제 이미지 숫자',Y)
print('예측 숫자',np.argmax(Y_infer.detach().cpu().numpy()))
plt.imshow(X.detach().cpu().numpy()[0],cmap='gray')
[ 출 처 ] “서울대 출신 AI 연구직의 세상에서 제일 쉬운 머신러닝 101,CNN예제-MNIST 다시 풀어보기.” CLASS101,2021년 04월 03일,https://class101.net/classes/5fb27988ca3e5d000dcbf6e4/contents/5fb29823da51e50013db0c7a