logloss
Page content
Log Loss란?
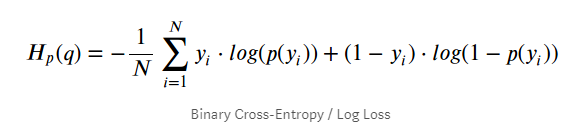
- 모델 성능 평가 시 사용가능한 지표
- 분류 모델 평가 시 사용
- 확률값을 기준으로 평가

예를 들어 오지선다 객관식 문제를 국진학생과 성진학생이 풀고 있다고 가정한다.
국진 학생은 구구단을 열심히 외운 학생입니다 그래서 문제를 보자마자 99%확률로 정답은 1번
15이다라고 판단하고 1번을 고릅니다.
반면 성진학생은 아직 구구단을 다외우지 못했습니다 그래서 20% 확률로 정답을 찍기로 결심합니다 그런데 얼떨결에 1번을 찍게 되어서 문제를 맞추게 되었습니다.
단순히 정답을 맞추는 여부로 두 학생을 평가하게 된다면 두 학생은 문제를 맞추었으므로 국진 학생과 성진학생이 실력이 같다고 평가 받게 됩니다.
하지만 확률 값에서 볼 수 있듯이 사실 국진학생이 성진 학생보다 학습을 열심히 한 학생이라고 볼 수 있습니다. 왜냐하면 국진학생은 99% 확률롤 정답을 획득하였고 성진학생은 20% 확률로 찍었기 때문이죠 허나 최종 맞춤 결과값의 개수로 평가하게 되면 이러한 차이를 반영하지 못하게 됩니다. 이러한 문제를 해결하기 위해서는 확률 값을 직접적으로 평가 지표로 활용하면 됩니다.
예를 들어 국진 학생한테는 0.99 점을 성진 학생한테는 0.2점을 부여하게 된다면 국진학생이 자신에게 더 걸맞는 평가를 받을 수 있습니다. 이렇게 확률 값을 기준으로 평가하게 된다면 국진 학생과 성진 학생이 동등하게 평가되는 문제를 해결할 수 있습니다.
즉 두 학생을 보다 더 정교하게 평가하는 것이죠.
요약
-
모델이 예측한 확률 값을 직접적으로 반영하여 평가
-
확률 값을 음의 log함수에 넣어서 변환 시킨 값으로 평가 –> 잘못 예측할수록, 패널티를 부여하기 위함(직관적 해석)
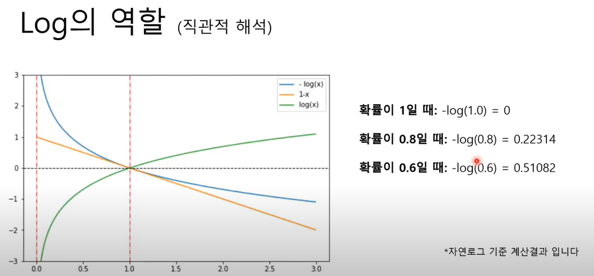
실제 정답에 대해서 예측을 못할수록 로그 함수의 특성에 따라서 페널티를 더 부여하게 된다. 기하급수적으로 페널티가 부여되는 것을 확인할 수 있다.
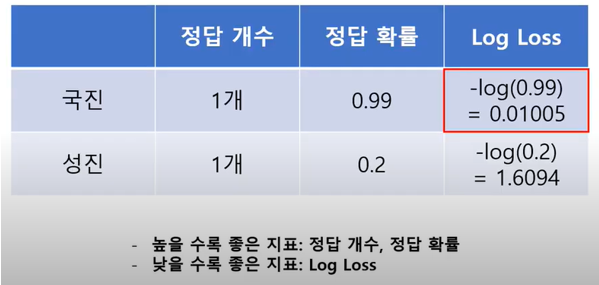 대부분의 머신러닝 분류모델들에서 예시에 등장한 학생들처럼 주어진 문제를 해결할 때 확률 값을 산출하여 최종적으로 분류할 클래스를 선정하게 됩니다. 그래서 logloss를 평가산식으로 사용하게 된다면 모델을 좀 더 정교하게 평가할 수 있다.
대부분의 머신러닝 분류모델들에서 예시에 등장한 학생들처럼 주어진 문제를 해결할 때 확률 값을 산출하여 최종적으로 분류할 클래스를 선정하게 됩니다. 그래서 logloss를 평가산식으로 사용하게 된다면 모델을 좀 더 정교하게 평가할 수 있다.
관측치(ROW)가 여러 개일 경우
관측치별로 실제 답안에 해당하는 확률 값을 음의 로그 취하고 평균을 냅니다.
[ 참 고 ] https://www.youtube.com/watch?v=i5U2inxzXx4,데이콘