2. NoSQL의 대표적인 데이터베이스 mongoDB
Page content
빅데이터란?
빅 데이터란 기존 데이터베이스 관리도구의 능력을 넘어서는 대량(수십 테라바이트)의 정형 또는
심지어 데이터베이스 형태가 아닌 비정형의 데이터 집합조차 포함한 데이터로부터 가치를 추출하고 결과를 분석하는 기술이다.
즉, 기존의 데이터 베이스로는 수집 · 저장 · 분석 · 처리하기 어려울 정도로 방대한 양의 데이터를 의미한다.
-
빅데이터 기술
기존의 데이터를 만개를 처리하는 기술과 수십만개의 데이터를 처리하는 기술이 다르다. 기존의 기술로는 수천만건의 데이터를 짧은 시간안에 처리하고 분석하기 어려워 새로운 기술이 나왔고 그 기술을 통칭하여 빅데이터 기술이라 부른다.
-
기존 데이터 처리 기술, 관계형 데이터베이스(RDBMS)
- SQL 언어로 사용 가능
- SQL 데이터 베이스
- MySQL, Oracle, PostgreSQL, SQLite
-
빅데이터 : NoSQL 데이터베이스
NoSQL의 이해
NoSQL이 RDBMS와의 다른 점으로는
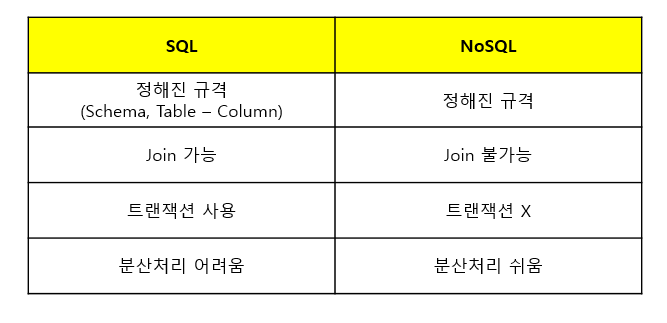
- 스키마가 없다. 즉 데이터 관계와 정해진 규격(table - column의 정의)이 없다.
- 관계정의가 없으니 JOIN이 불가능 하다.
- 트랜잭션을 지원하지 않는다.
- 분산처리(수평적 확장)를 쉽게 제공한다.( 대부분의 NoSQL DB는 분산처리기능을 목적으로 나왔기 때문에 분산처리 기능을 자체 프레임워크에 포함하고 있다 )
왜 NoSQL을 사용하는가?
- RDBMS를 기본으로 사용하지만,
- 초당 데이터가 수십만개씩 쌓이는 서비스가 많아지면서, NoSQL을 사용하는 경우가 많아지고 있음
- 경험적 수치
- 95% read, 5% write 경우는 RDBMS가 성능이 나쁘지 않음
- 50% write > 인 경우 RDBMS는 성능 저하 또는 불안정
- NoSQL + Redis(In memory cache)등을 고려하게 됨
NoSQL DB 종류
- NoSQL 데이터베이스는 각 데이터베이스마다 기반으로 하는 데이터 모델이 다르므로, 데이터 모델별로 대표적인 데이터베이스를 알아둘 필요가 있음
- NoSQL 데이터베이스의 종류는 키-값 데이터베이스, 도큐먼트 데이터베이스, 칼럼 패밀리 데이터베이스, 그래프 데이터베이스로 나뉘며
- 아래 그림은 관계형 데이터베이스와 4가지 종류의 NoSQL 데이터베이스를 각각의 대표 제품과 함께 나타낸 그림이다.
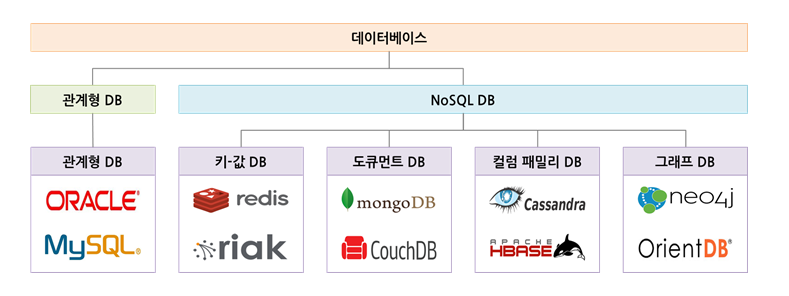
- 키-값 데이터베이스 : 키와 값으로 구성된 배열구조의 데이터베이스로 NoSQL 데이터베이스 중 가장 단순한 구조
- 도큐먼트 데이터베이스 : 필드와 값의 형태로 구성된 데이터를 JSON 포맷으로 관리하는 데이터베이스로 NoSQL 데이터베이스 중 가장 인기가 높음
- 칼럼 패밀리 데이터베이스 : 칼럼과 로우로 구성된 데이터베이스로 칼럼은 이름과 값으로 구성되고 로우는 각기 다른 칼럼으로 구성이 가능
- 그래프 데이터베이스 : 노드와 관계로 구성된 데이터베이스로 근접한 객체를 모델링할 목적으로 설계
mongoDB란?
-
mongoDB는 document db
- JSON 기반의 Document 기반 데이터 관리
-
데이터 포맷
- 정수(int), 소숫점(float), 문자(string)
- csv, JSON
- JSON –> { id : “hun”, “language” : “korean”, “edition” : “first” }
-
mongoDB Document 예 )
{ “_id” : ObjectId{“403321312431523614543124”}, “username” : “JiHunSeo”, “name”: { first: “JiHun”, last: “Seo” } <- sub document }
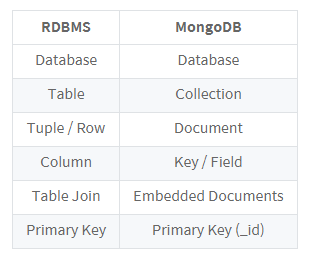
MongoDB 데이터 구조
- Database - Collection(table대신) - Document(low 대신에, column이라는 개념이 없다.)
- RDBMS : Database - Table - data
- RDBMS의 table이 아니라 collection에 JSON 형태의 Document를 넣음
- Document 하나가 하나의 로우(레코드)임
mongoDB Database
- Database는 Collection의 집합
MongoDB Collection
- Collection은 mongoDB Document의 집합
- RDBMS Table과 유사한 개념, 단 정규화된 데이터 구조, 즉 Schema가 정의되어 있지 않음
mongoDB 특징과 장단점
- RDBMS와 비교
- 특징과 장단점
- 2-1. 특징
- Document-oriented storage : MongoDB는 database > collections > documents 구조로 document는 key-value형태의 BSON(Binary JSON)으로 되어있다.
- Full Index Support : 다양한 인덱싱을 제공한다.
- Single Field Indexes : 기본적인 인덱스 타입
- Compound Indexes : RDBMS의 복합인덱스 같은 거
- Multikey Indexes : Array에 미챙되는 값이 하나라도 있으면 인덱스에 추가하는 멀티키 인덱스
- Geospatial Indexes and Queries : 위치기반 인덱스와 쿼리
- Text Indexes : String에도 인덱싱이 가능
- Hashed Index : Btree 인덱스가 아닌 Hash 타입의 인덱스도 사용 가능
- Replication& High Availability : 간단한 설정만으로도 데이터 복제를 지원. 가용성 향상.
- Auto-Sharding : MongoDB는 처음부터 자동으로 데이터를 분산하여 저장하며, 하나의 컬렉션처럼 사용할 수 있게 해준다. 수평적 확장 가능
- Querying(documented-based query) : 다양한 종류의 쿼리문 지원. (필터링, 수집, 정렬, 정규표현식 등)
- Fast In-Pace Updates : 고성능의 atomic operation을 지원
- Map/Reduce : 맵리듀스를 지원.(map과 reduce 함수의 조합을 통해 분산/병렬 시스템 운용 지원, 하둡처럼 MR전용시스템에 비해서는 성능이 떨어진다)
- GridFS : 분산파일 저장을 MongoDB가 자동으로 해준다. 실제 파일이 어디에 저장되어 있는지 신경 쓸 필요가 없고 복구도 자동이다.
- Commercial Support : 10gen에서 관리하는 오픈소스
- 2-2. 장점
- 쌓아놓고 삭제가 없는 경우가 제일 적합하다. (ex. 로그데이터, 세션 등)
- Flexibility : Schema-less라서 어떤 형태의 데이터라도 저장할 수 있다.
- Performance : Read & Write 성능이 뛰어나다. 캐싱이나 많은 트래픽을 감당할 때 써도 좋다.
- Scalability : 애초부터 스케일아웃 구조를 채택해서 쉽게 운용가능하다. Auto sharding 지원
- Deep Query ability : 문서지향적 Query Language 를 사용하여 SQL 만큼 강력한 Query 성능을 제공한다.
- Conversion / Mapping : JSON형태로 저장이 가능해서 직관적이고 개발이 편리하다.
2-3. 단점
- 정합성이 떨어지므로 트랜잭션이 필요한 경우에는 부적합하다. (ex. 금융, 결제, 회원정보 등)
- JOIN이 없다. join이 필요없도록 데이터 구조화 필요
- memory mapped file으로 파일 엔진 DB이다. 메모리 관리를 OS에게 위임한다. 메모리에 의존적, 메모리 크기가 성능을 좌우한다. 2-4를 참고하자.
- SQL을 완전히 이전할 수는 없다.
- B트리 인덱스를 사용하여 인덱스를 생성하는데, B트리는 크기가 커질수록 새로운 데이터를 입력하거나 삭제할 때 성능이 저하된다. 이런 B트리의 특성 때문에 데이터를 넣어두면 변하지않고 정보를 조회하는 데에 적합하다.