빅데이터 분석기사 필기 요약
Page content
빅데이터 이해
정형데이터 : 통계저 분석을 수행할 수 있는 테이블 형태로 정리된 데이터
반정형 데이터 : 규격화된 형식을 가지지 않는 웹 문서, 신문과 같은 데이터. 주로 XML,JSON 포맷
- 데이터 속성을 표기하는 메타데이터를 가지며 데이터 구조는 일관성이 없으므로 테이블의 형식을 하고 있어도
샘플들의 속성 순서가 모두 다를 수 있다.
비정형 데이터 : 특별한 형식을 가지지 않는 텍스트, 이미지, 오디오와 같은 원시 데이터
- 형태와 구조가 복잡하여 기존의 DB에 저장될 수 없다, 정형 데이터로 변환되어 분석해야 한다.
연관 규칙 학습 : 변수간에 연간된 상관관게
유형 분석 : 조직화, 그룹화 어느 유형인지
유전 알고리즘 : 유전[진화] -> 최저 솔루션 찾음
머신러닝 : 데이터로 학습, 예측[유튜브 추천]
회귀분석 : 독립변수,종속변수. A-> B에 어떤 영향을 주는가?
감정분석 : 어떤 글이나 말에서 감정을 분석
소셜네트워크분석, 오피니언 리더, 영향력 있는 사람
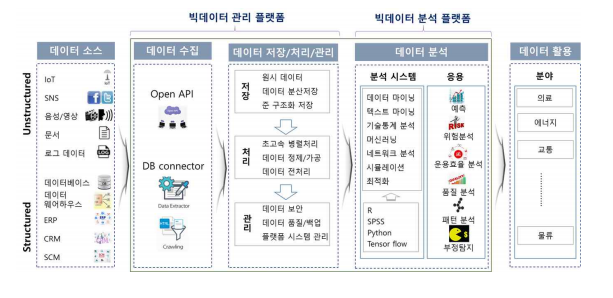 출처 : https://ksp.etri.re.kr/ksp/plan-report/read?id=687
출처 : https://ksp.etri.re.kr/ksp/plan-report/read?id=687
빅데이터 관리 플랫폼 : 데이터를 수집하여 활용 가능한 형태로 저장,처리,관리 등을 수행하는
소프트웨어 플랫폼
ex) 하둡, HDFS, 맵리듀스, 스파크 등
빅데이터 분석 플랫폼 : 텍스트 마이닝, 인공지능, 알고리즘 등 분석기법을 활용해서 의미가 있는 인사이트 도출
ex) R,파이썬,Tensorflow,spotfire,Tableaue 등
빅데이터 에코시스템 : 관리플랫폼 + 분석플랫폼을 하나로 통합
ex) 하둡(Hadoop) 에코시스템 : 기업들이 Hadoop 기반 에코시스템 사용, 분산처리에 강점, 오픈소스
비정형 데이터 : IoT, SNS, 음성/영상, 문서, 로그 데이터
정형 데이터 : 데이터베이스, 데이터 웨어하우스, ERP,CRM,SCM
데이터수집 : 크롤링,로그수집기,센서네트워크,RSS Reader, Open API, ETL프로세스
하둡 데이터 수집: Sqoop,Flume,Kafka,Scribe,Chukwa,Strom,Avro
데이터 저장: DBMS, Hbase, Cassandra, Mongo DB, NoSQL, GFS(Google), HDFS
데이터 처리: Hadoop, Spark, MapReduce
데이터 분석 방법 : 데이터 마이닝, 텍스트 마이닝, 분류, 군집, 머신러닝, 감정분석, SNS분석 등
ETL : 추출 -> 변형 -> 적재
DW : 의사결정 및 분석에 도움을 주기 위해 분석 가능한 형태의 정보 창고
DM : USER 또는 팀, 사업단에게 제공되는 분석가능한 정보 저장공간
SCM[Supply Chain Management] : 원자재, 재고, 납품 등 공급관리
CRM[Customer Relationship Managemet]: 고객관계, 고객관리 등 거래관리
ERP[Enterprise Resourece Planning]: 기업 물적, 전사적 인적자원 관리
데이터 수집 및 저장 이해
정형 데이터 수집 6가지
FTP : 파일 송수신을 위해 고안된 서비스. TCP/IP 기반 프로토콜
API : 시스템 간 연동을 통해 데이터를 실시간으로 수신할 기능을 제공하는 소프트 웨어
SQOOP : SQL + HADOOP 정형 데이터를 분산처리시스템에 수집해서 저장하는 기술
RYSNC : 리눅스 방식으로 1:1 서버 클라이언트 파일과 디렉토리 연결
DB TO DB : 데이터베이스 간 동기화 및 전송
ETL : 추출-변형- 적재
반정형 데이터 수집 5가지
플럼,스크라이브,척와 –> 로그 데이터 수집
플럼
로그데이터 흐름 수집 및 전달
Data Generator -> Source -> Channel -> Sink -> HDFS(하둡 분산 파일 시스템)
Agent : Souce -> Channel -> Sink
플럼을 실시간 데이터 스트리밍을 지원하지 않으므로 그 대안으로 실시간 데이터 스트리밍을 지원하는 KAFKA(실시간 로그데이터 흐름을 봄)가 사용될 수 있다.
webserver -> KAFKA -> Source(KAFKA source) -> Channel(KAFKA Channel) -> Sink -> Hadoop,Hbase
척와
분산된 로그를 Agent로 수집, HDFS에 저장, 실시간 분석기능
에이전트 : 척와 에이전트가 데이터를 직접 수집하지는 않고, 어댑터(adapter)에서 수집한다.
어댑터는 에이전트 프로세스 안에서 실행되며, 데이터를 실제로 수집하는 역할을 하낟.
컬렉터 : 에이전트로부터 전송된 데이터를 주기적으로 하둡 파일 시스템에 저장한다.
이때 한 컬렉터는 여러 대의 에이전트 서버로부터 데이터를 전송받지만, 이를 하나의 파일에 저장한다.
컬렉터 저장하는 파일을 싱크(sink)파일이라고 부르며, 하둡 파일 시스템의 SequenceFile 포맷으로 저장
스크라이브 : 실시간 스트리밍 로그데이터 수집
스트리밍 : 센서 Data, 오디오 등 미디어 수집
센싱 : 센서 Data를 네트워크로 수집
비정형 데이터 수집 5가지
크롤링 : 웹사이트에서 정보, 뉴스, SNS 소식 등 웹문서 또는 웹 콘텐츠를 웹을 돌아다니며 수집
스크래파이 : 파이썬 언어 기반 웹크롤링 프레임워크
아파치 카프카 : 실시간 로그처리를 위한 분산 스트리밍 플랫폼
Producers -> KAFKA CLUSTER(=Broker) : message log -> Consumers
RSS[Rich Site Summary] : XML 기반으로 정보를 배포하는 프로토콜을 활용. 블로그, 뉴스, 쇼핑몰 등 글을 수집.
OPEN API : 누구나 사용할 수 있도록 공개 된 API(실시간 정보 제공)
인터넷 웹 결과를 인터넷 화면(UI)에 제공받는 것에 그치지 않고 직접 data를 받아서(웹언어 등) 직접 응용프로그램과 서비스를 개발가능
Data 척도 4가지
명목척도 : 분류 자체가 의미. 수치화, 연산 X
ex) 혈액형, 거주지역, 우편번호
서열척도 : 상대적 비교, 수치는 순서일뿐
ex) 시험 석차, 학년
등간척도 : 각각의 개별평가, 등간(동일간격), (상중하), 미세먼지[나쁨, 보통,좋음]
ex) 온도, 지수, 토익점수(0~990)
비율척도 : 곱셈, 비율연산 존재, 평균계산가능, 절대원점 존재(0은 없음을 뜻함)
ex) 몸무게, 키, 넓이, 길이, 부피 등등
Data 변환 5가지 암기
평활화(Smoothing) : 노이즈(잡음), 이상치 제거
집계(Aggregation) : 그룹화 총계, 부분합 ex) 월별 합계
일반화(Generalization) : 특정 구간에 분포하는 값으로 Scale 변경 ex) m -> km
속성생성(Attribute Construction) : 분포를 속성/특징으로 대표
ex) 생년월일로 나이대 생성 -> 30대,40대,50대
토끼, 사자, 사슴 등등을 묶어서 동물로 지칭
정규화(Normalization) : 데이터를 정해진 구간 내로
1. min-max 정규화 : 0 ~ 1사이
2. z-score 정규화 : 평균에서 몇 표준편차 떨어져 있는가
3. Decimal 정규화 : 소숫점 조정
NoSQL vs RDMBS 차이
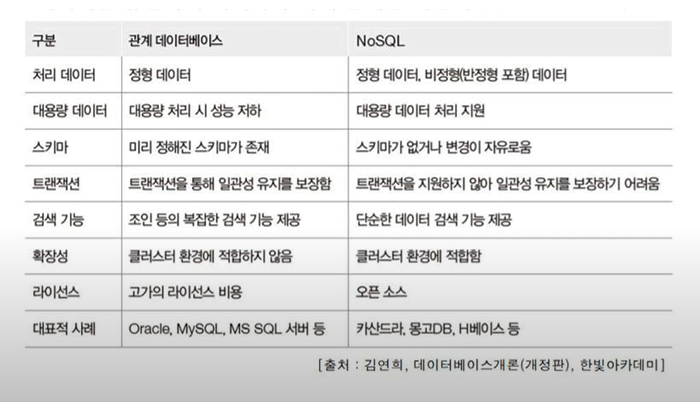
SQL(RDBMS)
- 정형데이터
- 고정된 스키마, 수직적
- Join 연산 가능
- 트랜젝션 O -> 일관성
- ACID 요건 충족
- 대용량시 문제
- Oracle, MySQL 등
NO SQL(Not Only)
- 정형,비(반)정형 데이터
- 고정된 형식 X, 수평적
- Join 없음.
- 트랜젝션 지원 X
- BASE 요건 충족
- 대용량
- 카산드라, 몽고DB,HBase
NoSQL 4가지 형태
- Key-Value Store : 특정 Key값을 주면, Value를 얻음
ex) Riak, Redis, DynamoDB
- Document Store : Key와 Document 형식 저장
ex) Mongo DB(중요), Couch DB, Orient, Raven
- Column Family Store : 특정 Key를 주면 Column 기반 Data Set 존재
ex) Cassandra(중요), HBase(중요), Hypertable
- Graph : 그래프 Node들로 표현
ACID(트랜잭션 관리를 위한 RDBMS 설계원리)
트랜잭션(Transaction)이란? : DB의 상태를 변화시키기 위한 작업 -> SQL을 통해서 DB 접근 및 수정하는 작업
- 원자성(Atomicity) : 성공 or 실패만 존재, 부분성공 x
- 일관성(Consistency) : 일관된 상태를 유지함.
- 고립성(Isolation) : 트랜잭션 완료전에 다른데서 확인 X
- 지속성(Durability) : 실행된 트랜잭션은 되돌릴 수 없음
CAP 이론(분산시스템 셋팅을 위한 중요한 정리)
클러스터에서 수행되는 분산 DB 시스템은 3가지중 2개까지만 동시에 수행가능
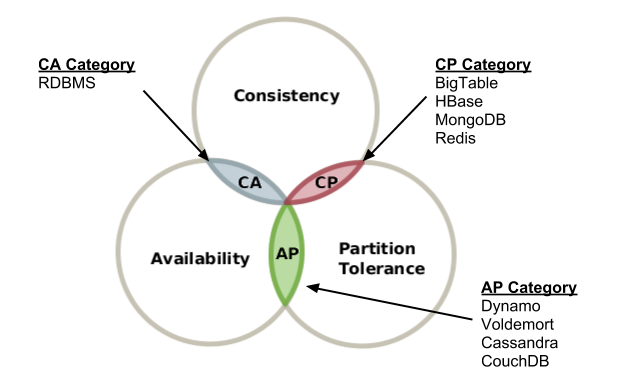 출처 : http://eincs.com/2013/07/misleading-and-truth-of-cap-theorem/
출처 : http://eincs.com/2013/07/misleading-and-truth-of-cap-theorem/
일관성(Consistency) : 분산환경에서 모든 노드가 같은 시점의 데이터를 보여줘야함
가용성(Available) : 모든 사용자가 읽고/쓰기 가능(노드장애에도)
여러 노드가 있을 때 하나가 망가지더라도 나머지 노드는 정상 동작
그리고 '노드에 장애가 있더라도 실패했습니다.' 전송
분할내성(Partition Tolerence) : 일부 데이터의 손실이 있더라도 시스템은 돌아가야함
C + A : P포기 -> 분할포기, RDBMS
C + P : A포기 -> 노드 문제 발생시 해결되고 가능, 성능문제
A + P : C포기 -> 데이터 일관성 문제, 모든 사람 동일 데이터 X
NO SQL BASE 요건
BASE지원?(NO SQL)
CAP 이론을 기반으로 분산기술을 사용하는 DB를 설계하는데 사용하는 원리, RDBMS(SQL)의 ACID요건 완화
사용가능한(Basically : 부분 고장이 있더라도 사용가능
Available) 주서버 고장에도 백업서버 작동
소프트 상태(Soft State) : 일관성이 없는 상태에서 Data 읽기 가능. 현시점 최신상태 읽음.
궁극적 일관성(Eventual consistency) : 일시적으로 일관성이 깨질 수 있다.(네트워크 문제, 시스템 부하 등)
동시간대에는 일관성을 유지할 수는 없지만 시간이 흘러 최종적으로는 복구가 됨
데이터 적재
수집한 Data를 저장시스템인 RDBMS, NOSQL, HDFS(하둡)에 데이터를 적재함
로그 Data 적재 Tool : Fluentd, Log_stash, Flume, Scribe
NOSQL DBMS 제공 적재 Tool : csv파일형태 -? mongoimport
RDBMS 제공 적재 Tool : 큰 변화 없이 그대로일 경우 SQLtoNOSQLimporter, Mongify
로그데이터 적재 4가지
플루언티드(Fluentd) : 중앙 로그저장소로 전송.
로그 트래픽 속도 조절.
로그스태쉬(Log-Stash) : 많은 Log Data를 하나의 저장소로 출력.
플럼(Flume) : 많은 양의 로그데이터 효율적으로 수집 및 저장
스크라이브(Scribe) : 실시간 스트리밍 Log Data 수집 및 저장
분산파일시스템(Distributed File System)
분산된 서버에 파일을 저장하고 저장된 데이터를 빠르게 처리할 수 있게 만든 시스템
구글 파일 시스템(GFS : Google File System)
하둡 분산 파일 시스템(HDFS: Haddop Distributeed File System)
구글의 GFS : 청크, 클라이언트, 마스터
맵리듀스 : Map + Reduce
하둡 HDFS : yarn, spark
하둡에코시스템 : hive, pigm, impala, zookeeper, oozie
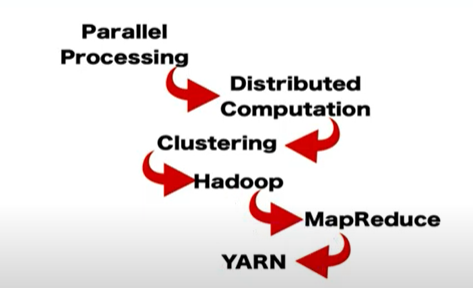 출처 : 한국데이터산업진흥원
출처 : 한국데이터산업진흥원
Divide and Conquer 알고리즘
복잡한 문제를 여러개의 단순한 문제로 바꾼 뒤 해결
가장 큰 장점 -> 병렬성(Parallesim) -> 기존에는 슈퍼컴퓨터가
병렬처리 : 여러 개의 프로세스를 통해 독립된 문제를 동시에 처리함
클러스터 : 여러대의 컴퓨터가 연결된 하나의 시스템처럼 동작하는 컴퓨터의 집합
저렴한 컴퓨터 + 네트워크 + 소프트웨어(분산처리)
데이터 분산저장
샤딩(Sharding) : 데이터를 작은 단위(샤드)로 수평적으로 분할해서 저장
샤드(Shard) : 수평으로 분할된 데이터 한 단위, 샤드를 모으면 전체 데이터셋
복제(Replication) : 데이터 세트 전체의 복사본을 다른 노드에 저장
레플리카(Replica) : 복제된 데이터 셋트 한 단위
마스터(Master) : 읽고,저장 가능한 데이터셋 원본
슬레이브(Slave) : 읽기만 가능한 복제된 데이터 셋
사용자가 데이터를 쓰기(Write) 작업 시 마스터(Master) 데이터 변경
변경된 데이터는 각 노드 슬레이브로 복제 읽기 작업시 슬레이브에서 읽기(Read)
GFS(Google File System)
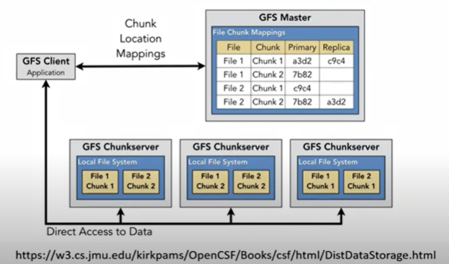
구글파일시스템
구글 클라우드 시스템을 위한 저비용, 고효율 분산저장 시스템 니즈 필요. 구글에서 개발
Fault Tolerance : 네트워크, 하드, CPU 등 장애조치가 원만해야 함
Scalability : 다수 사용자, 수 많은 서버 등등. 확장성
Auto Computing : 관리,모니터가 힘듦 -> 자동 할당
청크(Chunk) : 구글파일시스템(GFS)에서 파일을 나누는 조각 한 단위
1개의 청크(Chunk)는 64MB 고정된 크기로 분할 저장
마스터 : 단일마스터, 파일 메타정보 저장, 하트비트msg
청크서버 : 청크 저장, 청크 파일처리, 하트비트(고장 여부)를 마스터에 전달
클라이언트 : 마스터에 청크인덱스요청. 청크 읽기/쓰기
구글 맵리듀스
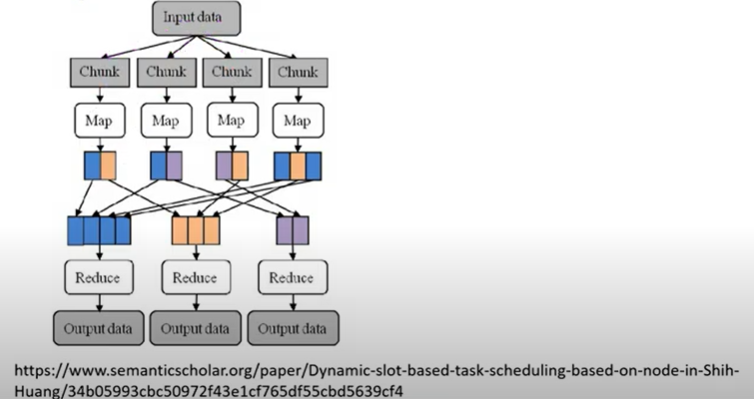
Map(맵) : (key, value)
Reduce(리듀스) : (key_new, value_new)
구글 맵리듀스 개발 배경
-
구글 검색(검색언어 추출, 정렬, 인덱스 생성 등)을 위해 개발된 분산환경 병렬 데이터 처리 기법
-
비공유 구조의 여러 노드 PC로 대량의 병렬처리 가능
-
데이터는 키-밸류(key,value)의 쌍으로 존재
Map : GFS에서 전달된 청크 단위(64MB)의 데이터를 (Key, value) 형태의 파일들로 데이터 기록 Reduce : Map 과정에서 분할 및 정리된(key, value) 데이터를 그룹화, 집계 후 GFS에 새로운 (key, value)로 저장
맵리듀스 장점
Fault Tolerance : 네트워크, 하드 CPU 등 장애에 유용
Easy to Use : Map함수, Reduce 두 개 함수로 병렬처리 구현
Locality Backup Task : 로컬 서버에 데이터를 부분적으로 읽고 처리 부분 백업 가능
맵리듀스 단점
실시간 처리에는 적합하지 않다. 주어진 시간 내로 처리하는 것은 유용하나 실시간 작업에는 적합X