머신러닝 회귀 모델의 평가지표
Page content
회귀 평가 지표
회귀 평가를 위한 지표는 실제 값과 예측값의 차이를 기반으로 함
회귀 평가지표 MAE, MSE, RMSE, RMSLE는 값이 작을수록 회귀 성능이 좋은 것 값이 작을수록 예측값과 실제값의 차이가 없다는 것을 의미
MSE(Mean Squared Error)
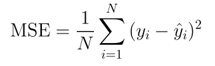 실제 값과 예측 값의 차이를 제곱해 평균한 것
실제 값과 예측 값의 차이를 제곱해 평균한 것
장점
- 지표 자체가 직관적이고 단순하다.
단점
스케일에 의존적이다. 예를 들어 테슬라의 주가가 900000원이고 현대자동차의 주가가 250000일 때,
두 주가를 예측하는 각각의 모델의 MSE가 똑같이 4000이 나올 경우, 분명 동일한 에러율이 아님에도
불구하고 동일하게 보여진다.
에러를 제곱하기 때문에, 1미만의 에러는 더 작아지고, 그 이상의 에러는 더 커진다.
즉 값의 왜곡이 존재한다.
MAE(Mean Absolute Error)
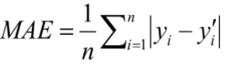 실제 값과 예측 값의 차이를 절댓값으로 변환해 평균한 것
실제 값과 예측 값의 차이를 절댓값으로 변환해 평균한 것
장점
지표 자체가 직관적이며 예측변수와 단위가 같다.
ex) 기온을 예측하는 모델의 MAE가 3이라면 이 모델은 평균적으로 3도 정도를 잘못 예측하는 것임
단점
잔차에 절댓값을 씌우기 때문에 실제 값에 대해 underestimates or overestimates 인지 파악하기 힘들다.
ex) 삼성전자의 주가를 예측하는 모델의 MAE가 1,000이라면 이 모델이 평균적으로 주가를 1000원을 높게 예측하는지 1000원을 낮게 예측하는지 파악하기 힘들다.
스케일에 의존적이다. (MAE, MSE, RMSE와 동일)
ex) 비트코인의 가격이 25,000,000이고 이더리움의 가격이 600,000 일 때 두 암호화폐의 가격을 예측하는 모델의 MAE가 동일하게 10,000 이라고 해보자.
이들은 분명 동일한 에러율이 아님에도 불구하고 MAE 숫자 자체는 동일하다
RMSE (Root Mean Squared Error)
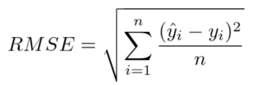 MSE 값은 오류의 제곱을 구하므로 실제 오류 평균보다 더 커지는 특성이 있어 MSE에 루트를 씌운 RMSE 값을 씀
MSE 값은 오류의 제곱을 구하므로 실제 오류 평균보다 더 커지는 특성이 있어 MSE에 루트를 씌운 RMSE 값을 씀
장점
지표 자체가 직관적이며 예측변수와 단위가 같다.
ex) 기온을 예측하는 모델의 RMSE가 3이라면 이 모델은 평균적으로 3도 정도를 잘못 예측하는 것임
잔차를 제곱하기 때문에 이상치에 민감하다.
제곱된 잔차를 다시 루트로 풀어주기 때문에 잔차를 제곱해서 생기는 값의 왜곡이 MSE에 비해 좀 덜하다.
단점
실제 값에 대해 underestimates or overestimates 인지 파악하기 힘들다.
스케일에 의존적이다. (MAE, MSE, RMSE와 동일)
RMSLE (Root Mean Squared Log Error)
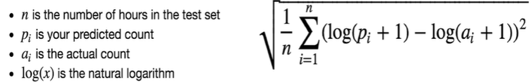 오차(Error)를 제곱(Square)해서 평균(Mean)한 값의 제곱근(Root)으로 값이 작을 수록 정밀도가 높음
오차(Error)를 제곱(Square)해서 평균(Mean)한 값의 제곱근(Root)으로 값이 작을 수록 정밀도가 높음
-
0에 가까운 값이 나올 수록 정밀도가 높은 값
-
과대평가 된 항목보다는 과소평가 된 항목에 패널티를 줌
-
RMSE와 비교해서 RMSLE가 가진 장점
-
아웃라이어에 강건함
RMSLE는 아웃라이어가 있더라도 값의 변동폭이 크지 않음
-
상대적 Error를 측정
RMSE와 달리 RMSLE는 예측값과 실제값의 상대적 Error를 측정
-
Under Estimation에 큰 패널티를 부여
과대 평가이던 과소 평가이던 간에 RMSE값은 동일함
RMSLE는 Under Estimation일 때 (즉, 예측값이 실제값보다 작을 때) 더 높은 페널티가 주어짐