pseudo labeling
Page content
Pseudo Labeling
-
Pseudo Labeling이란? Labeled Data처럼 일일히 label을 하기보다, 이미 가지고 있는 Labeled data에 기반하여 대략적인 Labled을 주는 것
-
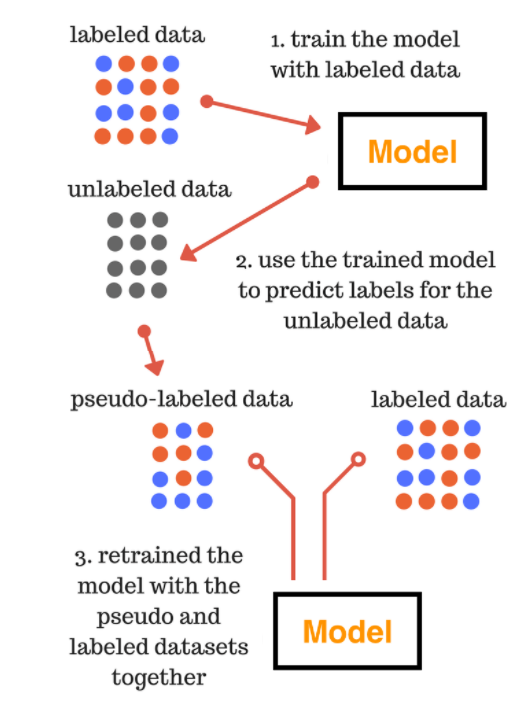
Pseudo Labeling의 순서
-
Labeled Data로 Model을 먼저 학습시킨다.
-
그렇게 학습된 모델을 사용하여, Unlabeled Data를 예측하고 그 결과를 Label로 사용하는 Pseudo-labeled data를 만든다.
-
Pseudo-labeled data와 Labeled를 모두 사용하여 다시 그 모델을 학습시킨다.
-
Pseudo Labeled data
- Pseudo Label은 아래와 같은 식으로, 각각의 sample에 대해, 예측된 확률이 가장 높은 것으로 정합니다.
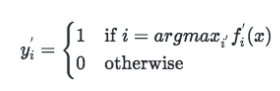{kind=link}
-
예측된 확률이 가장 높은 것을 Label로 선정한다고 했을 때, 제대로 학습을 마치지 못한 모델로 이 작업을 하였을 경우에는 상식적으로 더 학습을 저해하는 데이터를 만들 뿐입니다.
-
그래서 Pseudo Label은 학습을 Labeled data로 일정 수준까지 마친 뒤의, fine-tuning phase에 시행합니다.
Pseudo-Label로 성능향상이 가능한 이유
-
Model의 전반적인 성능을 높이기 위해서는 Model의 Decision boundary는 Low-densidy regions에 위치해야한다.
-
Decision Boundary를 결정할 때, 그 경계를 구분하는 지점의 데이터가 몰려있는 밀도가 낮으면 낮을수록, 더 미세한 차이점도 구별한다고 생각할 수 있기 때문에, 전체적인 성능을 높일 수 있다.
'경계를 구분하는 지점의 데이터'라는 말은 경계를 구분해야 하는 곳에 있는 데이터. 즉, 구별하기 힘들다는 말이다. 구별하기 힘든 데이터들이 많이 모여있으면 그 곳의 밀도가 높아지고, 반대로 구별하기 힘든 데이터들의 수가 작다면 밀도 또한 낮다는 말이 된다. 그러면 0이 뭉쳐있는 그룹과, 1이 뭉쳐있는 그룹. 또 각각 총 10개의 그룹이 서로 명확하게 구별이 되면 될수록, 서로 헷갈리지 않으니 그 그룹들을 구분짓는 경계에 떡하니 있는 구별이 힘든 데이터가 작다는 말이 되고, 즉, 그 밀도가 낮을 수록 더 미세한 차이점도 구별하는 똑똑한 모델이라고 볼 수 있다.
출처 : https://www.stand-firm-peter.me/2018/08/22/pseudo-label/