Blending 기법
Page content
예측값을 변수로 활용하는 앙상블 테크닉 Blending
Blending 은 Ensemble 의 한 종류입니다. Ensemble 이란 예측 모형을 통합해서 하나의 예측을 수행하는 것을 말합니다. Ensemble 의 묘미는 서로 다른 예측 모형들을 합쳐 더 강한 예측 모형을 만들 수 있다는 것입니다. 가령 정확도 0.7, 0.7 인 모델 두 개를 합쳐서 0.9 을 만들 수 있습니다.
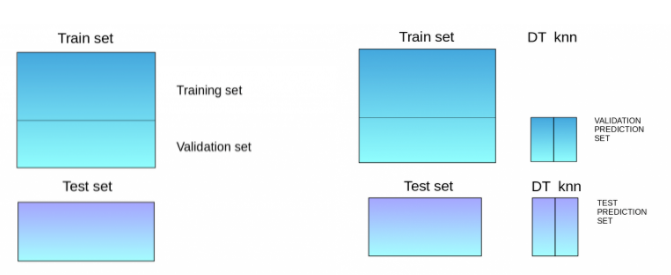
Blending 의 프로세스
1. Traning/Validation/Test set 을 나눈다.
2. Training set 에 모델 피팅을 한다.
3. Validation/Test set 에 대해 예측을 한다.
4. Validation set 과 Validation set 에 대한 예측이 새로운 모델을 만드는 데에 사용된다.
5. 4의 모델을 최종 Test set 에 대한 예측을 하는데 사용된다.
# train, test로 분리
# X : data , y : target
x_train, x_test, y_train, y_test = train_test_split(X, y,
test_size =0.2,
stratify=y, # target의 class 비율에 맞춰서 분리
random_state = 1 )
# Train set을 Train/Validation set로 분리
x_train, x_val, y_train, y_val = train_test_split(X_train, y_train,
test_size=0.2, stratify=y_train,
random_state=1)
model1 = tree.DecisionTreeClassifier()
model1.fit(x_train, y_train)
val_pred1=model1.predict(x_val)
test_pred1=model1.predict(x_test)
val_pred1=pd.DataFrame(val_pred1)
test_pred1=pd.DataFrame(test_pred1)
model2 = KNeighborsClassifier()
model2.fit(x_train,y_train)
val_pred2=model2.predict(x_val)
test_pred2=model2.predict(x_test)
val_pred2=pd.DataFrame(val_pred2)
test_pred2=pd.DataFrame(test_pred2
아래 코드는 validation set 의 예측 결과 (Decision tree, KNN) 을 원래 feature 에 붙여서 새로운 데이터셋 df_val 을 만든 후, Final prediction model (이 예제에서는 Logistic regression model) 을 적합시키고, test set 에 대한 예측을 수행하는 것입니다.
df_val=pd.concat([x_val, val_pred1,val_pred2],axis=1)
df_test=pd.concat([x_test, test_pred1,test_pred2],axis=1)
model = LogisticRegression()
model.fit(df_val,y_val)
model.score(df_test,y_test)
Blending 과 Stacking 의 차이점
Blending 은 종종 다른 Ensemble technique 인 Stacking 과 비교가 됩니다.
Stacking 은 다른 예측 모형들의 결과값을 통해 새로운 모델을 만드는 Ensemble 방법입니다.
Stacking 의 경우는 Training set 의 예측값을 Training data 로 하여 Meta classifier (또는 Meta regression) 을 학습합니다.
그리고 이 Meta classifier 를 통해 Test set 을 예측합니다.
Blending 과 Stacking 의 차이점은 1) Blending 은 validation set 에 대한 예측값을 training 에 이용하지만, Stacking 은 training set 에 대한 예측값을 활용합니다.
2) Blending 을 예측값 뿐 아니라 원래 Feature 도 활용하는 반면, Stacking 은 예측값만 활용합니다. 그러면 이러한 의문이 남습니다.
왜 validation set 만 활용해서 Final prediction model 을 구축해야하는가?
Training Set 에의 feature에 Training set 으로부터 예측한 예측값을 붙여서 활용하면 되지 않는가? 입니다.
만약 training performance 와 validation performance 가 비슷하다면 가능한 방법입니다. 하지만 training performance 가 높다면, feature 가 예측에 별로 필요하지 않게 됩니다.
따라서 feature를 예측에 활용하는 blending 의 장점이 없게 됩니다.
따라서 blending 을 잘활용하기 위해서는 validation set 의 meta-feature (원래 feature 및 예측값) 을 통해 training 하고, test set 에 대해 성능을 최종 평가해야합니다.