# 종속변수인 Chance_of_Admit(입학 허가 확률)와 독립변수(GRE, TOEFL, Univ_Rating, SOP,
# LOR, CGPA)에 대해 피어슨 상관계수를 이용한 상관관계 분석을 수행하고 그래프를 이용하여
# 분석결과를 설명하시오.
# 작업 디렉토리 설정
setwd("C:/ADP/data")
# 데이터 불러오기
adms <- read.csv("Admission.csv")
str(adms)
head(adms)
tail(adms)
sum(is.na(adms)) # NA값이 존재하는지 확인
# 종속변수인 Chance_of_Admit(입학 허가 확률)과 독립변수(GRE, TOEFL, Univ_Rating,
# SOP, LOR, CGPA)에 대해 피어슨 상관분석을 각각 수행한다.
# 1. GRE와 Chance_of_Admit 간의 상관분석
str(adms)
cor(adms$GRE,adms$Chance_of_Admit) # 피어슨 상관계수 산출
# [1] 0.8026105
cor.test(adms$GRE, adms$Chance_of_Admit)
# Pearson's product-moment correlation
# data: adms$GRE and adms$Chance_of_Admit
# t = 26.843, df = 398, p-value < 2.2e-16
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# 0.7647419 0.8349536
# sample estimates:
# cor
# 0.8026105
# 해석
# p-value가 0.05보다 작으므로, 두 변수간의 상관관계는 통계적으로 유의하다.
# 상관계수는 약 0.80으로 GRE와 Chance_of_Admit는 양의 상관관계를 가지고 있음을 알 수 있다.
# 2. TOEFL와 Chance_of_Admit 간의 상관분석
cor(adms$TOEFL, adms$Chance_of_Admit) # 피어슨 상관계수 산출
# [1] 0.791594
cor.test(adms$TOEFL, adms$Chance_of_Admit) # 피어슨 상관계수 검정
# Pearson's product-moment correlation
# data: adms$TOEFL and adms$Chance_of_Admit
# t = 25.845, df = 398, p-value < 2.2e-16
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# 0.7519028 0.8255675
# sample estimates:
# cor
# 0.791594
# p-value가 0.05보다 작으므로, 두 변수간의 상관관계는 통계적으로 유의하다.
# 상관관계는 약 0.79로 TOEFL와 Chance_of_Admit는 양의 상관관계를 가지고 있음을 알 수 있다.
# 3.Univ_Rating와 chance_of_Admit 간의 상관분석
cor(adms$Univ_Rating, adms$Chance_of_Admit) # 피어슨 상관계수 산출
# [1] 0.7112503
cor.test(adms$Univ_Rating, adms$Chance_of_Admit) # 피어슨 상관계수 검정
# Pearson's product-moment correlation
#
# data: adms$Univ_Rating and adms$Chance_of_Admit
# t = 20.186, df = 398, p-value < 2.2e-16
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# 0.6591685 0.7565413
# sample estimates:
# cor
# 0.7112503
# 해석
# p-value가 0.05보다 작으므로, 두 변수간의 상관관계는 통계적으로 유의하다.
# 상관계수는 0.71로 Univ_Rating와 chance_of_Admit는 양의 상관관계를 가지고 있음을 알 수 있다.
# 4. SOP와 Chance_of_Admit 간의 상관분석
cor(adms$SOP, adms$Chance_of_Admit) # 피어스 상관계수 산출
# [1] 0.6757319
cor.test(adms$SOP, adms$Chance_of_Admit) # 피어스 상관계수 검정
# Pearson's product-moment correlation
#
# data: adms$SOP and adms$Chance_of_Admit
# t = 18.288, df = 398, p-value < 2.2e-16
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# 0.6186712 0.7257010
# sample estimates:
# cor
# 0.6757319
# 해석
# p-value가 0.05보다는 작으므로, 두 변수간의 상관관계는 통계적으로 유의하다.
# 상관계수는 약 0.68로 SOP와 chance_of_Admit는 양의 상관관계를 가지고 있음을 알 수 있다.
# 5. LOR와 Chance_of_Admit 간의 상관분석
cor(adms$LOR, adms$Chance_of_Admit) # 피어슨 상관계수 산출
# [1] 0.6698888
cor.test(adms$LOR, adms$Chance_of_Admit) # 피어슨 상관계수 검정
# Pearson's product-moment correlation
# data: adms$LOR and adms$Chance_of_Admit
# t = 18, df = 398, p-value < 2.2e-16
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# 0.6120380 0.7206083
# sample estimates:
# cor
# 0.6698888
# 해석
# p-value가 0.05보다 작으므로, 두 변수간의 상관관계는 통계적으로 유의하다.
# 상관계수는 약 0.67으로 LOR와 Chance_of_Admit는 양의 상관관계를 가지고 있음을 알 수 있다.
#6. CGPA와 Chance_of_Admit 간의 상관분석
cor(adms$CGPA, adms$Chance_of_Admit) # 피어슨 상관계수 산출
# [1] 0.8732891
cor.test(adms$CGPA, adms$Chance_of_Admit) # 피어슨 상관계수 검정
# Pearson's product-moment correlation
#
# data: adms$CGPA and adms$Chance_of_Admit
# t = 35.759, df = 398, p-value < 2.2e-16
# alternative hypothesis: true correlation is not equal to 0
# 95 percent confidence interval:
# 0.8478354 0.8947275
# sample estimates:
# cor
# 0.8732891
# 해석
# p-value가 0.05보다 작으므로, 두 변수간의 상관관계는 통계적으로 유의하다.
# 상관계수는 약 0.87으로 CGPA와 Chance_of_Admit는 양의 상관계수를 가지고 있음을 알 수 있다.
# 상관계수 행렬 생성 및 시각화
cor(adms[,-7])
# GRE TOEFL Univ_Rating SOP LOR CGPA
# GRE 1.0000000 0.8359768 0.6689759 0.6128307 0.5575545 0.8330605
# TOEFL 0.8359768 1.0000000 0.6955898 0.6579805 0.5677209 0.8284174
# Univ_Rating 0.6689759 0.6955898 1.0000000 0.7345228 0.6601235 0.7464787
# SOP 0.6128307 0.6579805 0.7345228 1.0000000 0.7295925 0.7181440
# LOR 0.5575545 0.5677209 0.6601235 0.7295925 1.0000000 0.6702113
# CGPA 0.8330605 0.8284174 0.7464787 0.7181440 0.6702113 1.0000000
# Chance_of_Admit 0.8026105 0.7915940 0.7112503 0.6757319 0.6698888 0.8732891
plot(adms[,-7])

# 해석
# 상관계수 행렬의 숫자들은 모두 양수이며, 그래프의 산점도가 오른쪽으로 올라가는 직선의 형태를
# 지닌 것을 보아, 서로 양의 상관관계를 가지는 것을 확인할 수 있다.
# 상관계수를 시각화하기 위한 패키지 설치
install.packages("corrgram")
library(corrgram)
# 상관계수를 대각선의 형태로 시각화
# upper.panel = panel.conf : 우측상단에 상관계수와 신뢰구간을 나타내는 것을 의미함
corrgram(adms[,-7], upper.panel = panel.conf)
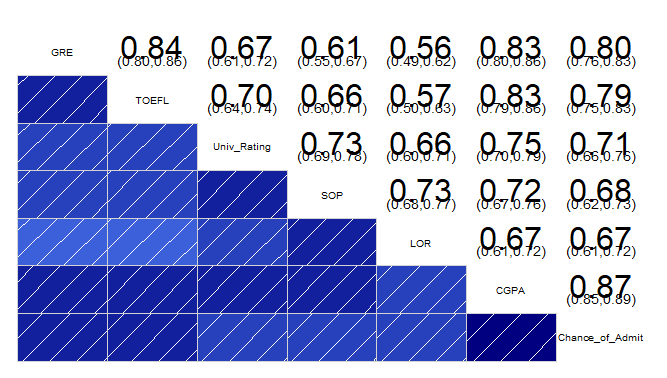
# 해석
# Admission 데이터에서 변수들의 이름은 대각선, 상관계수는 우측 상단에 배치하고
# 좌측하단에는 상관계수를 그림으로 표현한 그래프이다. 그래프의 대각선이
# 왼쪽아래에서 오른쪽위로 향하는 것은 두 변수가 양의 상관관계를 가지고 있음을 나타내고,
# 색의 짙기는 상관계수의 크기를 뜻하므로 상관계수의 절댓값이 클수록 색이 짙어진다.
#
# 그래프 상의 모든 대각선이 왼쪽 아래에서 오른쪽 위를 향하고 있으므로 모든 변수가
# Chance_of_Admit 변수와 양의 상관관계를 가지고 있음을 알 수 있다.
# 또한 CGPA와 Chance_of_Admit간의 상관관계를 나타내는 그래프의 색이 가장 짙으므로
# 둘 간의 상관성의 정도가 가장 크다고 해석할 수 있으며, 두변수간 상관계수는 약 0.87임을 알 수 있다.
# GRE, TOEFL, Univ_Rating, SOP, LOR, CGPA, Reasearch가 Chance_of_Admit에
# 영향을 미치는지 알아보는 회귀분석을 단계적 선택법을 사용하여 수행하고 결과를 해석하시오.
# 회귀모형 생성
str(adms)
adms.lm <- lm(Chance_of_Admit ~., data=adms)
# 회귀모형에 대한 정보 확인
summary(adms.lm)
# Call:
# lm(formula = Chance_of_Admit ~ ., data = adms)
#
# Residuals:
# Min 1Q Median 3Q Max
# -0.26259 -0.02103 0.01005 0.03628 0.15928
#
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) -1.2594325 0.1247307 -10.097 < 2e-16 ***
# GRE 0.0017374 0.0005979 2.906 0.00387 **
# TOEFL 0.0029196 0.0010895 2.680 0.00768 **
# Univ_Rating 0.0057167 0.0047704 1.198 0.23150
# SOP -0.0033052 0.0055616 -0.594 0.55267
# LOR 0.0223531 0.0055415 4.034 6.6e-05 ***
# CGPA 0.1189395 0.0122194 9.734 < 2e-16 ***
# Research 0.0245251 0.0079598 3.081 0.00221 **
# ---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
# Residual standard error: 0.06378 on 392 degrees of freedom
# Multiple R-squared: 0.8035, Adjusted R-squared: 0.8
# F-statistic: 228.9 on 7 and 392 DF, p-value: < 2.2e-16
# 해석
# 회귀분석 결과 상수항, GRE, TOEFL, LOR, CGPA, Reasearch 변수가 유의 수준 0.01이하에서
# 통계적으로 유의함을 확인할 수 있다. 모형의 결정계수는 0.8035, 수정된 결정계수는 0.8로
# 추정된 다변량회귀식은 전체 데이터의 약 80%를 설명하고 있다. 또한 회귀모형의 F통계량에 대한
# p-value는 0.05보다 작으므로 유의수준 0.05 하에서 모형이 통계적으로 유의한 것을 알 수 있다.
# 단계선택법을 통한 변수선택을 수행한다.
step(adms.lm, direction = "both")
# Start: AIC=-2193.9
# Chance_of_Admit ~ GRE + TOEFL + Univ_Rating + SOP + LOR + CGPA +
# Research
#
# Df Sum of Sq RSS AIC
# - SOP 1 0.00144 1.5962 -2195.5
# - Univ_Rating 1 0.00584 1.6006 -2194.4
# <none> 1.5948 -2193.9
# - TOEFL 1 0.02921 1.6240 -2188.6
# - GRE 1 0.03435 1.6291 -2187.4
# - Research 1 0.03862 1.6334 -2186.3
# - LOR 1 0.06620 1.6609 -2179.6
# - CGPA 1 0.38544 1.9802 -2109.3
#
# Step: AIC=-2195.54
# Chance_of_Admit ~ GRE + TOEFL + Univ_Rating + LOR + CGPA + Research
#
# Df Sum of Sq RSS AIC
# - Univ_Rating 1 0.00464 1.6008 -2196.4
# <none> 1.5962 -2195.5
# + SOP 1 0.00144 1.5948 -2193.9
# - TOEFL 1 0.02806 1.6242 -2190.6
# - GRE 1 0.03565 1.6318 -2188.7
# - Research 1 0.03769 1.6339 -2188.2
# - LOR 1 0.06983 1.6660 -2180.4
# - CGPA 1 0.38660 1.9828 -2110.8
#
# Step: AIC=-2196.38
# Chance_of_Admit ~ GRE + TOEFL + LOR + CGPA + Research
#
# Df Sum of Sq RSS AIC
# <none> 1.6008 -2196.4
# + Univ_Rating 1 0.00464 1.5962 -2195.5
# + SOP 1 0.00024 1.6006 -2194.4
# - TOEFL 1 0.03292 1.6338 -2190.2
# - GRE 1 0.03638 1.6372 -2189.4
# - Research 1 0.03912 1.6400 -2188.7
# - LOR 1 0.09133 1.6922 -2176.2
# - CGPA 1 0.43201 2.0328 -2102.8
#
# Call:
# lm(formula = Chance_of_Admit ~ GRE + TOEFL + LOR + CGPA + Research,
# data = adms)
#
# Coefficients:
# (Intercept) GRE TOEFL LOR CGPA Research
# -1.298464 0.001782 0.003032 0.022776 0.121004 0.024577
# 해석
# 변수선택을 통해 도출된 회귀모형
adms.lm2 <- lm(adms$Chance_of_Admit ~ adms$GRE + adms$TOEFL + adms$LOR + adms$CGPA + adms$Research, data=adms)
summary(adms.lm2)
# Call:
# lm(formula = adms$Chance_of_Admit ~ adms$GRE + adms$TOEFL + adms$LOR +
# adms$CGPA + adms$Research, data = adms)
#
# Residuals:
# Min 1Q Median 3Q Max
# -0.263542 -0.023297 0.009879 0.038078 0.159897
#
# Coefficients:
# Estimate Std. Error t value Pr(>|t|)
# (Intercept) -1.2984636 0.1172905 -11.070 < 2e-16 ***
# adms$GRE 0.0017820 0.0005955 2.992 0.00294 **
# adms$TOEFL 0.0030320 0.0010651 2.847 0.00465 **
# adms$LOR 0.0227762 0.0048039 4.741 2.97e-06 ***
# adms$CGPA 0.1210042 0.0117349 10.312 < 2e-16 ***
# adms$Research 0.0245769 0.0079203 3.103 0.00205 **
# ---
# Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
#
# Residual standard error: 0.06374 on 394 degrees of freedom
# Multiple R-squared: 0.8027, Adjusted R-squared: 0.8002
# F-statistic: 320.6 on 5 and 394 DF, p-value: < 2.2e-16
# 해석
# 단계선택법을 이용한 변수 선택을 수행한 후 선택도니 변수들로 회귀분석을 수행한 결과,
# 상수항, LOR,CGPA 변수들은 유의수준 0.0001 하에서 통계적으로 유의하며 GRE,TOEFL,Research 변수는
# 유의수준 0.01하에서 통계적으로 유의함을 확인할 수 있다.
#
# 모형의 결정계수는 0.8027 수정된 결정계수는 0.8002로 추정된 다변량회귀식은 전체 데이터의 약 80%를
# 설명하고 있다. 또한 회귀모형의 F-통계량에 대한 p-value값은 0.05보다 작으므로 유의수준 0.05하에서
# 모형이 통계적으로 유의한 것을 알 수 있다.
# 단계 선택법을 사용해 변수를 선택한 후 새롭게 생성한 회귀모형에 대한 잔차분석을 수행하고,
# 그래프를 활용하여 결과를 해석하시오.
# 잔차에 대한 세 가지 가정 중 독립성 가정을 만족하는지 확인한다.
install.packages("lmtest") # 더빈왓슨 검정을 위해 필요한 패키지 설치
library(lmtest)
dwtest(adms.lm2)
# Durbin-Watson test
#
# data: adms.lm2
# DW = 0.74991, p-value < 2.2e-16
# alternative hypothesis: true autocorrelation is greater than 0
# 해석
# 귀무가설(H0)는 잔차들 사이에 자기상관관계가 없다, 즉 독립적이다.
# 대립가설(Ha)는 잔차가 자기상관관계가 있다.
# 오차항의 독립성을 확인할 수 있는 DW(더빈-와트슨 통계량)이 0 ~ 4의 범위이며 2근처의 값이 나와야 자기상관관계가 없습니다.
#
# --> Durbin-Waston 검정 결과, Durbin-Waston 값이 0.74991로 0에 가까우며,
# p-value가 2.2e-16로 매우 작으므로, 귀무가설을 기각한다.
# 따라서 독립성 가정을 만족한다고 보기 힘들다.
# 잔차에 대한 세 가지 가정 중 정규성 가정을 만족하는지 확인한다.
# 정규성 가정을 만족하는지 확인
shapiro.test(resid(adms.lm2))
# Shapiro-Wilk normality test
#
# data: resid(adms.lm2)
# W = 0.92193, p-value = 1.443e-13
# 해석
# shapiro 검정 결과, p-value가 1.443e-13로 매우 작으므로, 귀무가설을 기각한다.
# 따라서, adms 데이터는 정규분포를 따른다고 보기 힘들다.
# 등분산성과 정규성 가정을 만족하는지 확인하기 위해 그래프를 통해 데이터를 시각화한다.
# 등분산성, 정규성 가정을 만족하는지 확인
par(mfrow=c(2,2))
plot(adms.lm2)
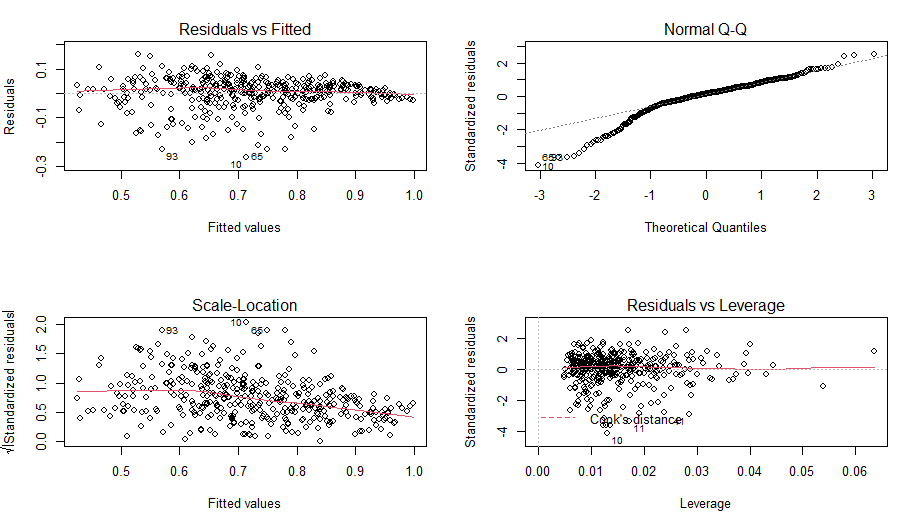
해석
1.Residuals(잔차) vs Fitted values(예측된 y값)의 분포(등분산성 가정 확인)
그래프의 기울기를 나타내는 빨간색 선이 직선의 성향을 띠고 있기 때문에 잔차는 평균인 0을 중심으로
고르게 분포함을 확인할 수 있다.
2. Q-Q Plot(정규성 가정 확인)
Q-Q Plot을 확인한 결과, 그래프의 대각선에서 벗어난 점들이 많이 있는 것으로 보아 adms의 데이터가
정규성을 만족한다고 보기 힘들다.
3. Scale-Location (등분산성 가정 확인)
빨간선의 기울기가 0에 가까워야 하지만, Fitted values가 커질수록 기울기가 줄어드는 경향을 보인다.
이렇게 빨간선의 기울기가 0에서 떨어진 점이 있다면 해당 점에서는 표준화 잔차가 큼을 의미하고,
회귀 직선이 y값을 잘 적합하지 못함을 의미한다. 또한 해당 점들은 이상치일 가능성이 있다.
4. Residuals(잔차) vs Leverage(레버리지) (영향력 진단)
그래프에서 쿡의 거리가 0.5이상이면 빨간 점선으로 표현됙, 점선 바깥에 있는 점들은 무시할 수 없을
정도로 예측치를 벗어난 관측값이다. 본 그래프에서 그러한 점은 보이지 않으므로 회귀직선에 크게
영향을 끼치는 점들은 드물다고 볼 수 있다.