# KoNLP 설치
writeLines('PATH="${RTOOLS40_HOME}\\usr\\bin;${PATH}"', con = "~/.Renviron")
usethis::edit_r_environ()
Sys.which("make")
install.packages("rJava")
install.packages("remotes")
remotes::install_github('haven-jeon/KoNLP', upgrade = "never", INSTALL_opts=c("--no-multiarch"))
useSejongDic()
install.packages(c("stringr", "hash", "tau", "Sejong", "RSQLite", "devtools"), type = "binary")
library(KoNLP)
library(plyr)
library(tm)
library(rJava)
library(wordcloud)
useSejongDic()
setwd("C:/ADP/data")
movie <- readLines("영화 기생충_review.txt")
dic <- readLines("영화 기생충_사전.txt")
buildDictionary(ext_dic = "woorimalsam", user_dic = data.frame(readLines("영화 기생충_사전.txt"),"ncn"),replace_usr_dic = T)
# KoNLP 패키지를 설치하고 useSejongDic 사전을 호출하였다. readLines 함수를 활용하여
# '영화 기생충_review.txt' 파일을 movie 데이터에, '영화 기생충_사전.txt' 파일을 dic 데이터에 저장했다.
# 그리고 buildDictionary 함수로 사전을 등록했다.
movie[1:10]
clean_txt <-function(txt){
txt <- tolower(txt) # 대,소문자 변환
txt <- removePunctuation(txt) # 구두점 제거
txt <- removeNumbers(txt) # 숫자 제거
txt <- stripWhitespace(txt) # 공백제거
return(txt)
}
movie_clean <- clean_txt(movie)
movie_clean[1:10]
# clean_txt라는 사용자 정의 함수를 만들어 tm 패키지에서 제공하는 tolower, removePunctuation, removeNumbers,
# stripWhitespace 함수를 활용하여 대,소문자 변환, 구두점, 숫자, 공백을 제거하여 movie_clean 데이터에 저장했다.
# 영화 기생충_사전.txt를 단어 사전으로 하는 TDM을 구축하고 빈도를 파악하고 시각화하라.
b <- VCorpus(VectorSource(movie))
clean_corpus <- function(corpus){
corpus <- tm_map(corpus, stripWhitespace)
corpus <- tm_map(corpus, removePunctuation)
corpus <- tm_map(corpus, removeNumbers)
corpus <- tm_map(corpus, content_transformer(tolower))
return(corpus)
}
c <- clean_corpus(b)
dtm <- TermDocumentMatrix(c, control = list(dictionary = dic))
m <- as.matrix(dtm)
v <- sort(rowSums(m), decreasing = TRUE)
d <- data.frame(word = names(v), freq=v)
head(d, 10)
# tm 패키지의 Corpus함수와 tm_map 함수를 활용해 전처리를 하고 TermDocumentMatrix를 dictionary를 사전에 저장한
# dic으로 하여 dtm에 저장했다. 그리고 matrix화하여 빈도를 내림차순으로 정렬하여 v에 저장하고
# d라는 data.frame로 변환하여 단어 빈도를 체크했다.
# 단어 빈도를 바탕으로 막대그래프를 작성한다
colors <- rainbow(nrow(d))
barplot(v[1:10], main="기생충 reiview 빈출 명사", col=colors)
legend("right",names(v[1:10]),fill=colors)
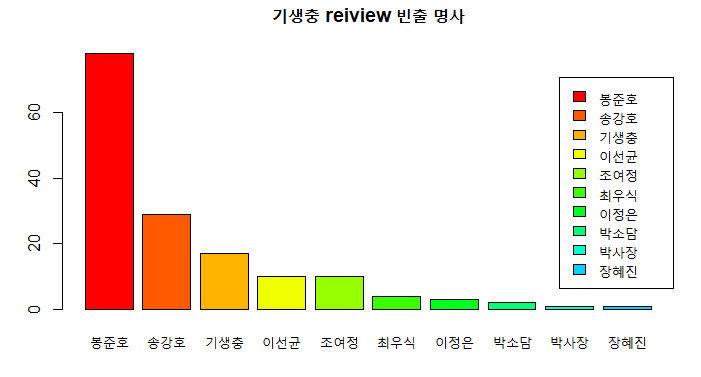
# barplot을 그린 결과, dic을 사전으로한 review에서는 봉준호 감독에 대한 언급이 가장 많았고
# 그 다음은 송강호, 기생충, 이선균 순이었다.
# extractNoun함수를 활용해 명사를 추출한 후, 2음절 이상이고, 최소 30번 이상 언급된
# 명사만 추출하여 워드클라우드를 작성한다.
# 명사 추출
movie_exN <- sapply(movie_clean,extractNoun)
Noun <- as.vector(unlist(movie_exN))
Noun_2 <- Noun[nchar(Noun)>=2]
# 워드클라우드 시각화
result <- data.frame(sort(table(Noun_2),decreasing=T))
t <- wordcloud(result$Noun_2,result$Freq,color=brewer.pal(8,"Dark2"),min.freq=30)

extractNoun 함수를 활용해 명사를 추출하고, 단어가 2음절 이상이고 최소 30번 이상 나타났던
명사만 추출하여 워드클라우드를 시각화 했다. 봉준호 감독에 대한 명사(봉준호, 감독 등)에 대한 단어와
영화에 관한 명사(송각호, 배우, 최고, 스토리, 현실, 황금종려상) 등이 나타났다. 해당 영화에 대한
'기대'라는 단어도 보이지만 '불편'이라는 단어가 나타난 것도 확인할 수 있다.