Lstm 이론
Page content
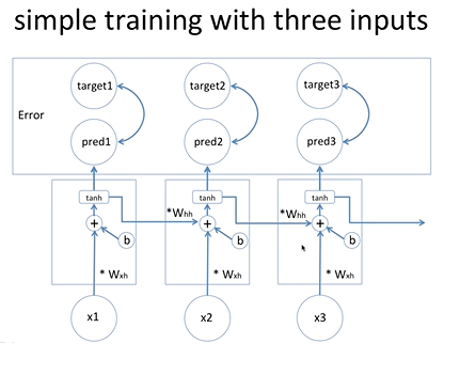
딥러닝은 학습하는데 있어서 주로 gradient descent를 사용하고 RNN 역시 gradient descent 사용
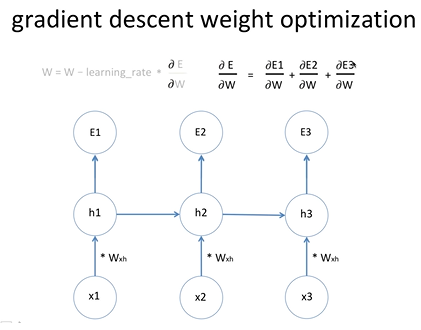
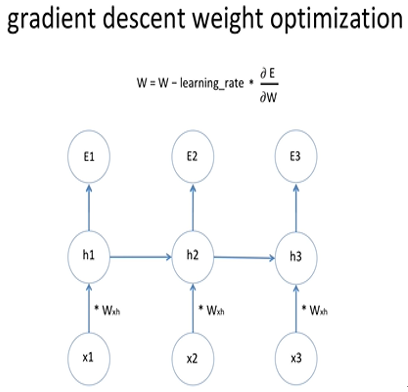
gradient desent 과정을 통해서 에러를 미분한 값은 E1의 에러값을 미분한 값, E2를 미분한 값, E3를 미분한 값과 같음
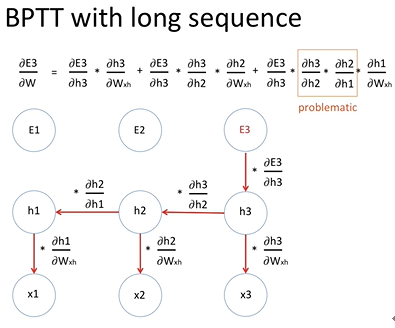
여기서 E3를 미분한 값을 보면 backpropagation through time을 통해서 여러 개의 미분값을 곱하게 되는데
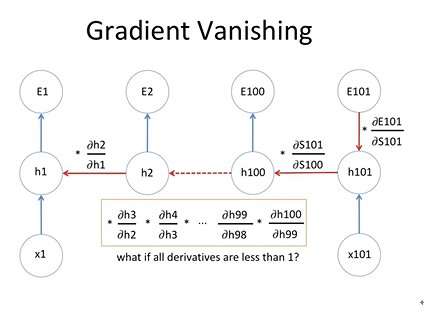
짧은 시퀀스 같은 경우 큰 문제가 없음
하지만 긴 시퀀스 같은 경우 예를 들어 100개 이상의 단어가 있는 문장이 있으면
곱하기를 100회 수행하게 되는데 만약 미분 값이 1보다 작을 경우 새로운 weight value는 기존의 weight value와
거의 차이가 없다. 즉 학습이 아무리 길어져도 weight value의 값이 거의 변하지 않음
이를 gradient vanishing 문제라고 합니다.
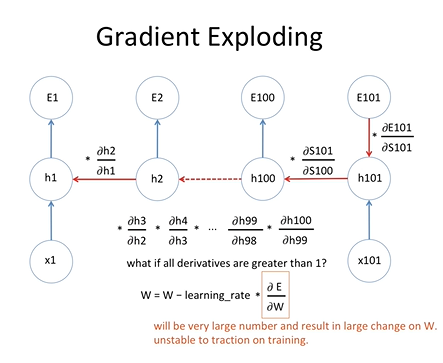
모든 미분 값이 1보다 클 경우에 이를 100번 이상 곱한다고 생각하면 상당히 값이 커질것이라고 생각할 수 있음
즉, 새로운 weight value는 기존의 weight value와 상당히 달라지게 되어있음 weight value의 변화폭이 크게 되며
학습의 방향이 한 곳으로 향하지 못하게 된다. 이를 gradient exploding 문제라고 합니다.
이러한 문제 때문에 시퀀스가 길어질 경우 RNN이 비효율적이다 이러한 문제를 해결하기 위해서 나온것이 LSTM이다.
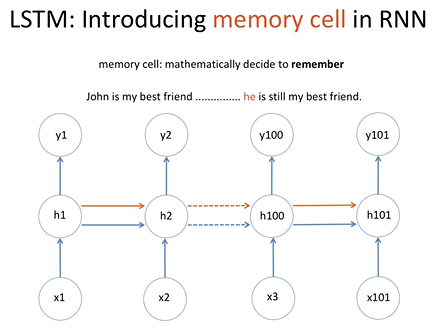
이와 같은 경우에 주어를 선택해야할 경우 memory cell은 john에 대한 정보를 계속 간직한 상태로 he라는 정보를 출력해야함
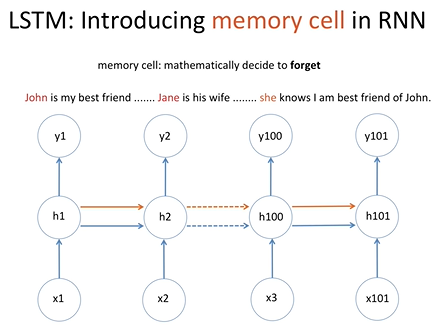
이와 같은 경우에 주어를 선택해야할 경우 memory cell은 john에 대해 잊고 jane에 대한 정보를 기억해야함.
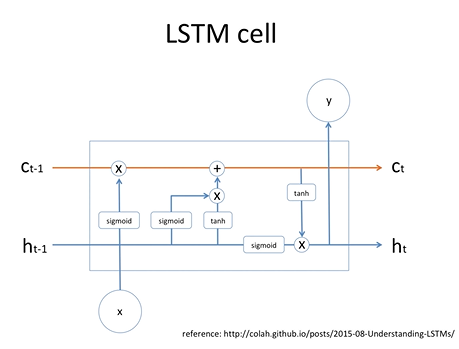
어떠한 정보를 잊는 메커니즘 어떠한 정보를 기억하는 메커니즘 이러한 것들이 LSTM 셀에 들어 있음.
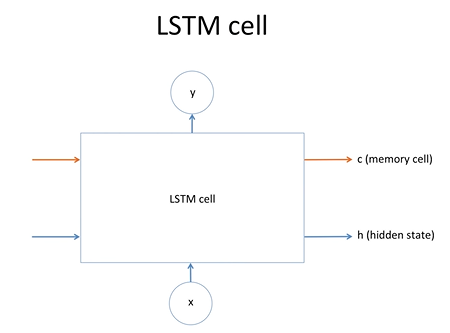
LSTM cell의 가장 간단한 모양이고 y 출력이 있으며 memory cell과 hidden state가 옆의 셀로 전파가 된다는 것을 알 수 있음
LSTM 메커니즘
LSTM 잊는 메커니즘
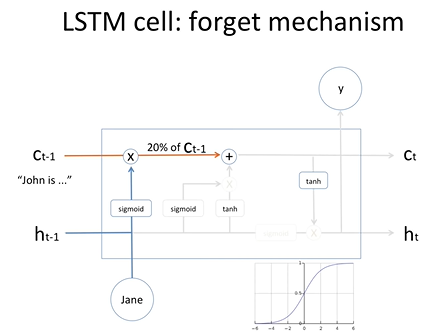
과거의 문장에 대한 정보 Ct-1(John에 대한 정보)
Jane 이라는 새로운 문장이 들어왔을 때 과거 은닉상태와 함께 시그모이드에 들어가게 된다.
이때 시그모이드의 출력값은 0~1로써 확률값이라고 이야기 할 수 있다.
만약 sigmoid 결과 20%라는 값이 나왔을 경우에 이것이 과거의 정보(Ct-1)와 곱해진 결과의 해석은
새로운 정보인 Jane이 들어왔을 때 과거의 정보를 20%만 간직하라는 의미이다.
학습과정을 통해서 forget mechanism의 weight value와 bias value가 optimize됨.
LSTM 새로운 정보를 추가하는 메커니즘
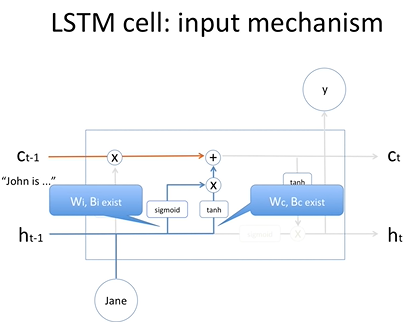
과거의 정보를 어느정도 잊었고 새로운 정보를 메모리셀에 추가해주는 부분.
과거 은닉상태와 현재 input이 들어와서 sigmoid 와 tanh가 곱해진다.
새로운 정보가 메모리셀에 더해지는 과정
학습과정을 통해서 input mechanism의 weight value와 bias value가 optimize됨.
LSTM 출력
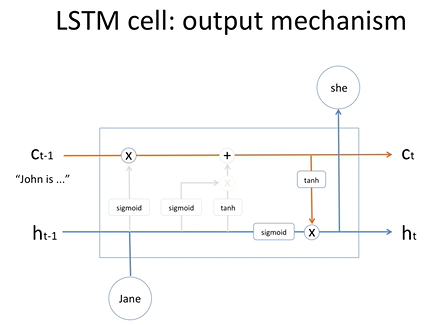
정보를 출력하고 state를 다음 셀에 전달한다.
메모리셀에 있는 정보가 tanh를 통해 들어오고 그리고 은닉상태와 현재의 정보가 시그모이드를 통해 들어와서
서로 곱한다. 이 곱해진 값이 output을 출력이 되고 이것이 다음 state로 전달된다.
출처 : [딥러닝] LSTM 쉽게 이해하기,https://www.youtube.com/watch?v=bX6GLbpw-A4