rnn in pytorch
Page content
RNN in PyTorch
파이토치에서는 nn.RNN()을 통해서 RNN 셀을 구현
import torch
import torch.nn as nn
입력의 크기와 은닉 상태의 크기를 정의
input_size = 5 # 입력의 크기
hidden_size = 8 # 은닉 상태의 크기
입력 텐서를 정의한다. 입력 텐서는 (배치 크기 x 시점의 수 x 매 시점마다 들어가는 입력)의 크기를 가진다.
배치의 크기는 1이며 10번의 시점동안 5차원의 입력 벡터가 들어가도록 텐서를 정의한다.
# (batch_size, time_steps, input_size)
inputs = torch.Tensor(1, 10, 5)
nn.RNN()을 사용하여 RNN의 셀을 만든다. 인자로 입력의 크기, 은닉 상태의 크기를 정의해주고, batch_first=True를 통해서 입력 텐서의 첫번째 차원이 배치 크기임을 알려준다.
cell = nn.RNN(input_size, hidden_size, batch_first=True)
입력 텐서를 RNN 셀에 입력하여 출력을 확인
outputs, _status = cell(inputs)
RNN 셀은 두 개의 입력을 리턴하는데, 첫번째 리턴값은 모든 시점의 은닉 상태들이며, 두번째 리턴값은 마지막 시점의 은닉 상태이다.
첫번째 리턴값에 대해서 크기 확인.
print(outputs.shape) # 모든 time-step의 hidden_state
첫번째 리턴값의 은닉 상태들은 (1, 10, 8)의 크기를 가진다. 이는 10번의 시점동안 8차원의 은닉상태가 출력되었다는 의미이다.
두 번째 리턴값. 다시 말해 마지막 시점의 은닉 상태의 크기를 확인.
print(_status.shape) # 최종 time-step의 hidden_state
Simple Example
예시 : Hell가 들어가면 다음 알파벳 o를 맞추기
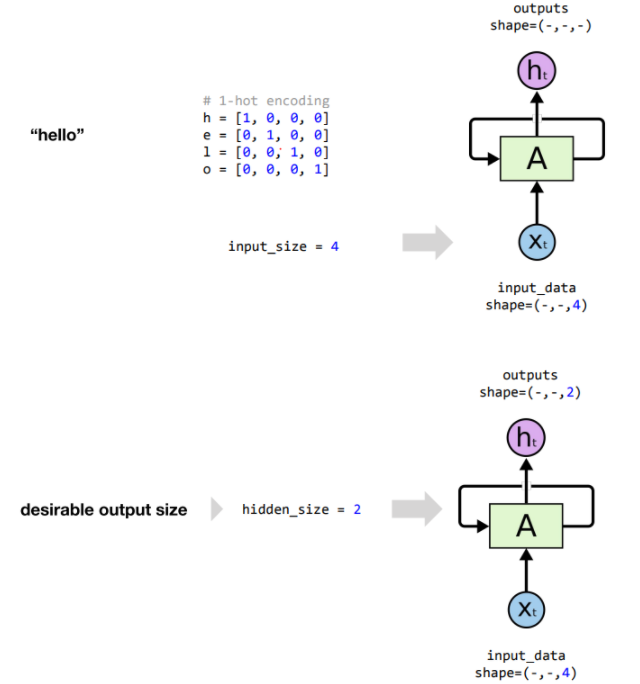
input_size : 4 (h의 차원의 크기 : [1, 0, 0, 0] )
hidden_size : 2 (특별한 이유는 없지만, 슬픔, 기쁨, 분노 중 하나를 추론한다면 3으로 둘 수 있음)
hidden_size의 크기가 outputs의 마지막 shape가 됨
이유는 아래의 첨부한 사진과 같음. hidden_state의 출력이 하나는 output으로 하고 다른 하나는 다음번 hidden_state로 가기에 둘은 같은 값을 가지게 됨
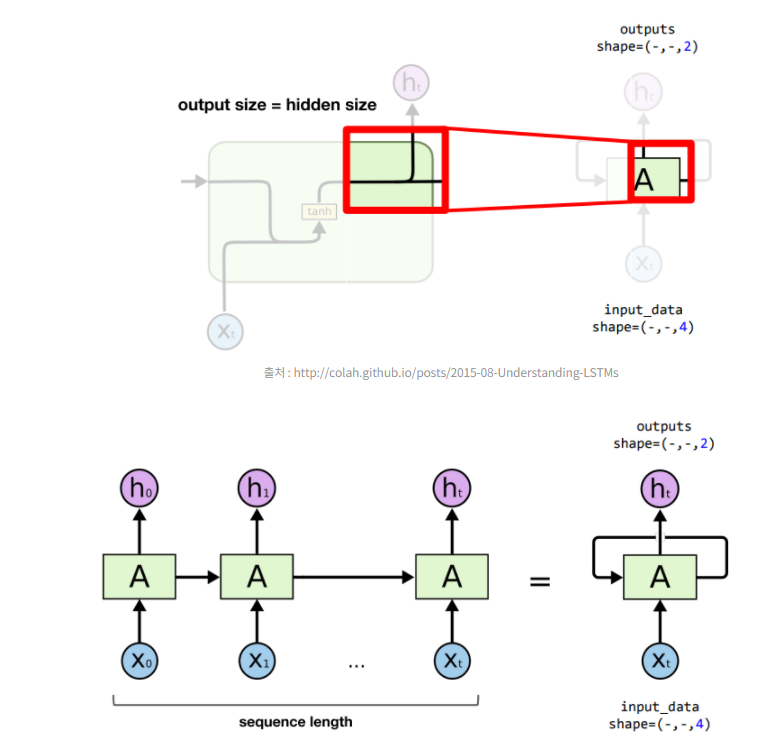
sequence length : 0부터 t까지의 길이를 가지는 입력값
예) h, e, l, l, o의 경우 sequence length는 5 output의 중간 shape가 sequence length가 됨(이건 모델이 알아서 인식함)
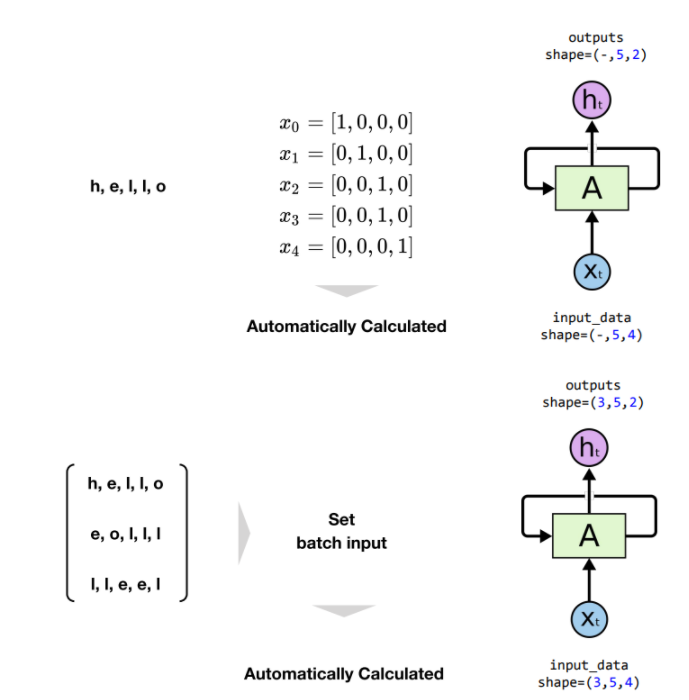
batch size 역시 모델에 입력할 필요가 없이 input data만 잘 구성하면 알아서 인식됨
import torch
import numpy as np
# Random seed to make results deterministic and reproducible
torch.manual_seed(0)
# declare dimension
input_size = 4
hidden_size = 2
timeseries
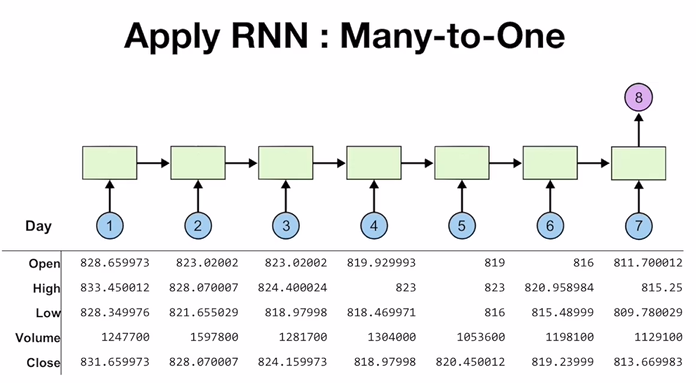
이 데이터를 넣는 모델을 보면 기본적으로 7일간의 데이터를 입력 받아서 8일차 종가를 예측하는 구조로 되어있다.
이 모델은 8일차의 종가를 예측하기 위해서 그전 일주일간의 데이터를 보면 될것이라는 전제로부터 출발한다. 그러나 주식시장에는 여러가지의 가정이 있기 때문에 옳지 않은 전제라고 볼 수 있으며 단지 이러한 전제로 출발했다는 사실을 알린다.
import torch
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# Random seed to make result deterministi and reproducible
torch.manual_seed(0)
# scaling function for input data
def minmax_scaler(data):
numerator = data - np.min(data, 0)
denominator = np.max(data, 0) - np.min(data, 0)
return numerator / (denominator + 1e-7)
# make dataset to input
def build_dataset(time_series, seq_length):
dataX = []
dataY = []
for i in range(0, len(time_series) - seq_length):
_x = time_series[i:i + seq_length, :]
_y = time_series[i + seq_length, [-1]] # Next close price
print(_x, "->", _y)
dataX.append(_x)
dataY.append(_y)
# hyper parameters
seq_length = 7 # 7일
data_dim = 5 # 시가,최고가,최저가,거래량,종가
hidden_dim = 10
output_dim = 1 # 마지막에 fully connected dimension이 맞춰야 하는 종가
learning_rate = 0.01
iterations = 500
# 파이토치가 읽을 수 있는 텐서의 형태로 변환
trainX_tensor = torch.FloatTensor(trainX)
trainY_tensor = torch.FloatTensor(trainY)
testX_tensor = torch.FloatTensor(testX)
testY_tensor = torch.FloatTensor(testY)
class Net(torch.nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, layers):
super(Net, self).__init__()
self.rnn = torch.nn.LSTM(input_dim, hidden_dim, num_layers=layers, batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, output_dim, bias=True) # fully connected layer 선언
def forward(self, x):
x, _status = self.rnn(x)
x = self.fc(x[:,-1])
return x
# start training
for i in range(iterations):
optimizer.zero_grad()
outputs = net(trainX_tensor)
loss = criterion(outputs, trainY_tensor)
loss.backward()
optimizer.step()
print(i, loss.item())
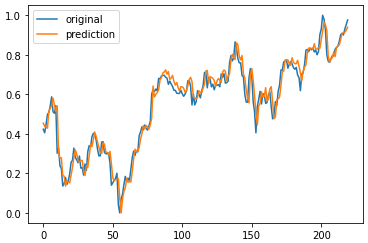
plt.plot(testY)
plt.plot(net(testX_tensor).data.numpy())
plt.legend(['original', 'prediction'])
plt.show()