인코더의 주 역할은 각 단어를 순차적으로 받음으로써 최종적으로 문맥 벡터를 만드는 것
디코더의 역할은 문맥 벡터로부터 기계번역을 시작
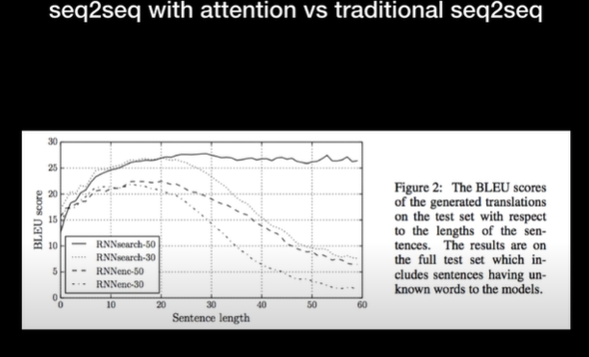
시퀀스가 적을 경우 문제가 없으나 시퀀스가 길어질경우 문제 발생
문맥 벡터는 고정된 사이즈의 벡터이므로 모든 정보를 함축하기에는 사이즈가 작다
그 대안으로 attention 메카니즘을 활용한다.
이전 인코더 디코더 아키텍처에서는 인코더에서 나왔던 모든 state를 활용하지 않았다
단순히 마지막에 나온 state를 context vector라고 불렀고 그 하나의 context vector에서 translation이 이루어졌다.
encoder 나온 각각의 rnn의 셀의 state를 활용하여 decoder에서 dynamic하게 context vector를
만들어 번역을 한다면 고정된 사이즈의 문제를 해결할 수 있다.
여기에서 얻는 장점 2가지
1. 고정된 사이즈의 문맥 벡터에서 발생한 문제를 각각의 state별로 context vector를 새로 만들어 해결
2. encoder에 있었던 모든 state 중에서 집중해야 할 단어들에게만 집중할 수 있는 메커니즘 설계 가능
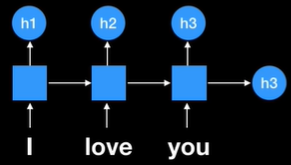
여기에서 h3는 전통적인 seq2seq에서는 context vector였다.
seq2seq with attention
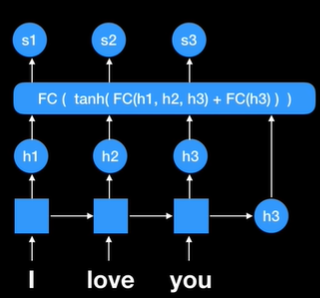
이번 방법을 보면 fully connected network가 있다.
보는 것처럼 h1,h2,h3 인코더 파트에서 나왔던 모든 rnn셀의 state를 활용하는 것을 볼 수 있음
그리고 최종에 나왔던 h3를 다시 넣었다. 지금 현재로써는 decoder에서 나온 값이 하나도 없기 때문에 단순히 전에 있었던 state 값을 넣어준 것이다.
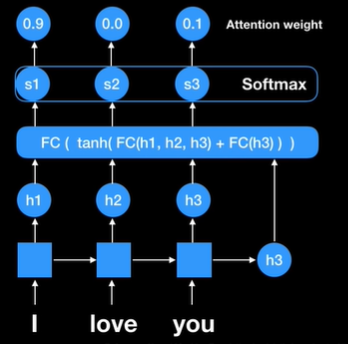
Fully connect network를 통해 나온 값은 score1, score2, score3이다 즉 각 인코더에 있던 rnn의 state score값이다
여기에 softmax를 취해주면 확률값이 나온다.
이것을 attention weight라고 부르고 이 값들은 얼마만큼 우리가 focus 할 것인지를 결정
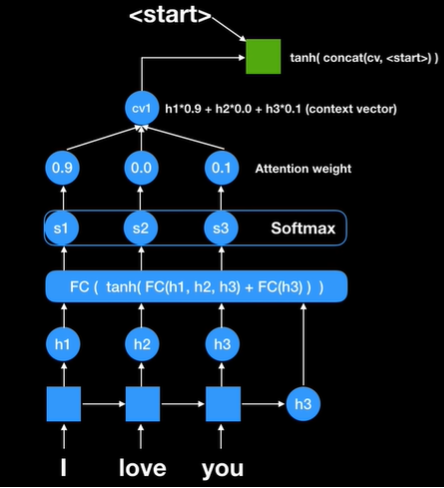
이렇게 첫번째 context vector를 만든다. 이것을 decoder 파트에 있는 첫번째 rnn 셀로 넣어주게 되고
지금까지 번역한 것이 없기 때문에 start라는 시그널을 넣어주게 된다.
First step으로 output이 나오게 되고
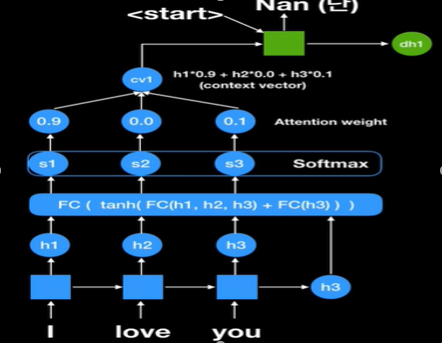
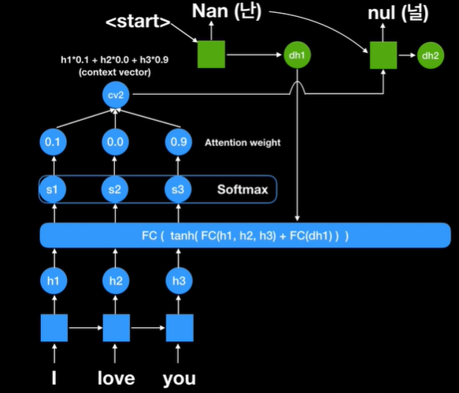
Second step으로 현재에 있는 decode의 state 값이 fully connected network에 들어가게 되고
여기에서 중요한 것은 h1,h2,h3가 항상 쓰인다는 것이다. 즉 인코더에 있는 rnn 셀들의 state값들이 항상 쓰인다는 것이다.
왜냐하면 이 값들 중에서 어떤 값에 우리가 주요하게 포커스를 할것인할 것 대해 계산을 해야하기 때문이다.
위의 그림을 보면 first step의 context vector와 다른 값인 것을 알 수 있다. 즉 단순히 한 개의 context vector만 사용한 과거의 seq2seq 모델보다 다이나믹하게 context vector를 만드는
seq2seq + attention 메커니즘이 방대한 양의 information을 함축하는데 있어서 더 효율적이다.
Context vector가 decoder의 두번째 rnn 셀에 들어가게 되고 이전 셀에 나왔던 output 값이 또 input으로 들어오게 된다.
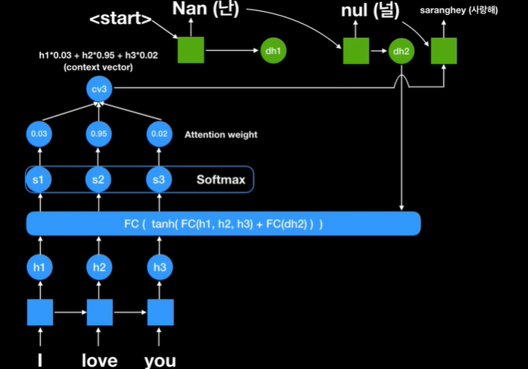
같은 방식으로 이번에는 dh2가 fully connected layer에 들어갔고 다시 한번 h1,h2,h3가 들어갔다.
이것들은 항상 필수로 들어가는데 왜냐하면 이 세 개 중에서 어떤 값에 더 집중할 것인지에 대해 관심이 있기 때문이다.
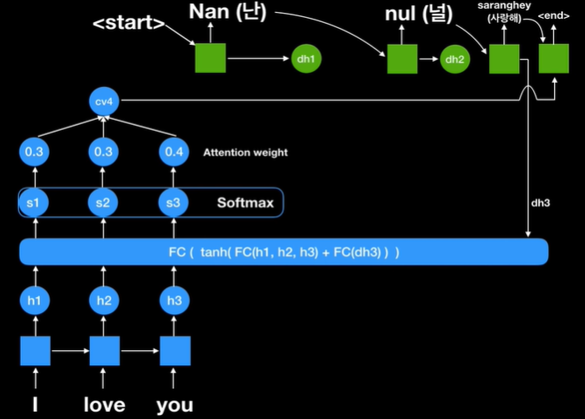
End가 나올때까지 반복
중요한 것은 attention weight ,인코더에 나온 state에서 어디를 focus 해서 볼 것인지에 대한 것이다.
Context vector가 각각 state 별로 decoding 할 때마다 달라진다.