StandardScaler()
Page content
사이킷런 데이터 전처리 함수 StandardScaler()
데이터의 피처 각각이 평균이 0, 분산이 1인 가우시안 정규분포를 가진 값으로 변환하는 작업을 표준화라고 한다.
기계학습 시에 SVM, 선형 회귀, 로지스틱 회귀는 가우시안 분포를 가정하고 구현되었으므로 전처리 단계에서 표준화를 해주는 것이 성능 향상에 도움이 된다.
원래 값에서 피처의 평균을 뺀 값을 피처의 표준편차로 나눠서 표준화한다. 수식으로 나타내면 다음과 같다.
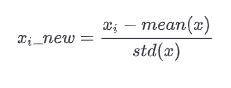
사이킷런의 StandardScaler를 사용해 표준화를 진행 할 수 있다. 데이터 인코딩에서와 마찬가지로 피처 스케일링에서도 fit()과 transform()을 사용한다.
표준화를 하는 이유
정규분포를 따르지만 평균과 표준편차가 각각 다른 현상들이 있을 때, 서로 비교하려면 표준화가 필요하다.
예를 들어 직무평가를 수행하였을 때 모든 직원들의 대인관계 점수의 평균이 50점이고 표준편차가 10이었고, 영향력 점수의
평균이 70점이고 표준편차가 20이었을 때, 어떤 직원이 대인관계 평가에서 70점을 맞았고 영향력 평가에서 85점을 맞았다.
어떤 평가점수가 더 우수하다고 판단할 수 있을까? 이런 상황에서 공정한 상대 평가를 위해 정규분포의 상대 평가가 필요하다.
정규 분포의 표준화는 평균이 m이고 표준편차가 인 정규 분포를 따르는 확률변수 X를 평균이 0이고 표준편차가 1인 표준정규분포를 따르는 확률변수 Z로 바꾸는 것을 의미한다.