Bayesian Optimization
만약 우리에게 모델이 있는데, 미지의 함수(black-box function)라 예측은 잘 되는데 그 속을 들여다 볼 수 없다.
즉, f(x)가 closed-form으로 표현되지 않는다.(닫힌 형태(closed form)란 방정식(equation)의 해(solution)를 해석적(analytic)으로 표현할 수 있는 종류의 문제를 말한다.)
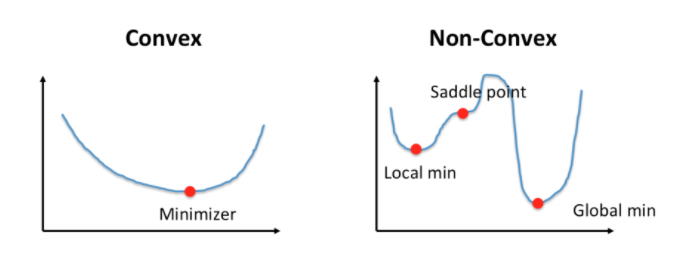
또 non-linear(비선형) + non-convex 해서 gradient도 찾을 수 없다.
Non-Convex한 함수란, 볼록함수와는 달리 극점이 굉장히 많을 수 있는 함수이기 때문에,
Gradient Descent를 통해 구한 최솟값이 Local Minumum일 뿐, Global Minimum값은 아닐 수 있는 가능성이 생긴다.
심지어 query를 입력으로 주고 evaluate 할 때 엄청난 시간/비용이 든다.
그래서 하이퍼파라미터를 튜닝하기 위해 여러번 시행착오를 겪을 수도 없다.
이렇게 우울한 모델이 있다면 어떻게 optimal model을 찾을 수 있을까?
가장 단순한 방법은 parameter를 grid로 나눠서 모든 모델을 만들어본다. (Grid Search) 하지만 생각만 해도 시간이 너무 많이 걸릴 것 같다.
그럼 grid를 모두 찾는게 아니고 random하게 parameter를 찍어볼 수 있다. (Random Search) 조금 빨리 찾을 가능성은 생기지만 역시나 효율적이진 않다.
이 때 효과적으로 하이퍼파라미터를 찾을 수 있는 훌륭한 방법으로 Bayesian Optimization를 사용할 수 있다.
Bayesian Optimization(이하 BO)는 어떤 함수가 최대/최소값을 갖게 하는 지점 x*를 찾는 일종의 Optimize 알고리즘이다.
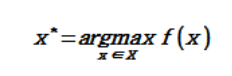 Bayesian Optimization(이하 BO)는 어떤 함수가 최대/최소값을 갖게 하는 지점 x*를 찾는 일종의 Optimize 알고리즘이다.
(AutoML은 BO를 적용할 수 있는 한 분야일 뿐, AutoML을 위한 알고리즘이 아니다.)
Bayesian Optimization(이하 BO)는 어떤 함수가 최대/최소값을 갖게 하는 지점 x*를 찾는 일종의 Optimize 알고리즘이다.
(AutoML은 BO를 적용할 수 있는 한 분야일 뿐, AutoML을 위한 알고리즘이 아니다.)
bayes_opt 패키지 사용법
- bayes_opt 패키지는 Baysian 방식으로 하이퍼 파라미터를 튜닝할 수 있도록 기능을 제공합니다. 일반적으로 하이퍼 파라미터가 많은 트리 기반의 ML 알고리즘이나 Deep Learning에 적용합니다.
- bayes_opt 패키지는 BaysianOptimization 클래스를 기반으로 하이퍼 파라미터를 최적화 하며, 프로세스는 아래와 같습니다.
- 이 BaysianOptimization 클래스의 생성 파라미터로 2개의 주요한 값을 입력 받습니다. 이 두개의 생성 파라미터는 모델의 성능을 평가하는 함수와 다양한 하이퍼 파라미터 유형과 값 범위를 기재한 Dictionary 입니다.
- 객체로 생성된 BaysianOptimization의 maximize() 메소드를 호출하면 객체 생성 파라미터로 입력된 모델 성능 평가 함수에 하이퍼 파라미 값을 입력하면서 최적의 하이퍼 파라미터 값을 찾습니다.
BaysianOptimization 객체 생성
from bayes_opt import BayesianOptimization
BO_lgb = BayesianOptimization(lgb_roc_eval, bayes_params, random_state=0
- lgb_roc_eval : 성능 평가를 수행할 함수
- bayes_params : 테스트 수행을 위한 파라미터 Dictionary
BaysianOptimization 객체는 생성 파라미터로 성능 평가 함수와 테스트를 위한 하이퍼 파라미터 Dictionary를 입력 받아야 하므로 객체 생성 이전에 먼저 이들을 정의해야 합니다.
bayes_params = {
'num_leaves': (24, 45),
'colsample_bytree':(0.5, 1),
'subsample': (0.5, 1),
'max_depth': (4, 12),
'reg_alpha': (0, 0.5),
'reg_lambda': (0, 0.5),
'min_split_gain': (0.001, 0.1),
'min_child_weight':(5, 50)
}
def lgb_roc_eval (num_leaves, colsample_bytree, subsample, max_depth, reg_alpha, reg_lambda, min_split_gain, min_child_weight):
1. Bayes_param은 하이퍼 파라미터를 Key로, 해당 하이퍼 파라미터에 입력될 값의 범위를 튜플 형태로 가지고있음.
즉 num_leaves: (24, 45)는 24 ~45까지의 값을 num_leaves에 입력. 이 때 유의할 점은 정수가 아닌
실수형 값을 입력한다는 것임. 즉 24.4, 24, 5가 입력 될 수 있으므로 이를 입력 받는 성능 평가 함수인 lgb_roc_eval 내에서 이들을 정수값으로 변환해야 함.
2. 성능 평가함수인 lgb_roc_eval( )은 인자로 bayes_param의 Key로 지정된 하이퍼 파라미터들을 받습니다.
3. 이렇게 성능 평가 함수가 만들어지면 이제 BaysianOptimization 객체를 Bayes Theorem 기반에서 최적의 하이퍼 파라미터로 가장 가능성 높은 값을 유추합니다.
성능 평가 함수 선언
def lgb_roc_eval(num_leaves, colsample_bytree, subsample, max_depth, reg_alpha, reg_lambda, min_split_gain, min_child_weight):
params = {
"n_estimator":200, "learning_rate":0.02,
'num_leaves': int(round(num_leaves)), # 호출 시 실수형 값이 들어오므로 정수형 하이퍼 파라미터는 정수형으로 변경
'colsample_bytree': colsample_bytree,
'subsample': subsample,
'max_depth': int(round(max_depth)),
'reg_alpha': reg_alpha,
'reg_lambda': reg_lambda,
'min_split_gain': min_split_gain,
'min_child_weight': min_child_weight
}
lgb_model = LGBMClassifier(**params)
lgb_model.fit(X_train, y_train, eval_set=[(X_test, y_test)], early_stopping_rounds=30, eval_metric="auc", verbose=100 )
valid_proba = lgb_model.predict_proba(X_test, num_iteration=best_iter)[:, 1]
roc_preds = roc_auc_score(y_test, valid_proba)
return roc_preds
모델을 학습 후 평가 수행한 뒤 성능 평가 지표(여기서는 roc_auc) 를 반환 반드시 지표를 반환해야 합니다. 그렇지 않으면 성능이 개선되는지 알 수 없습니다.
Bayesian Optimization으로 최적 하이퍼 파라미터 도출 작업 수행
# 최척 하이퍼 파라미터 도출 작업을 n_iter 만큼 반복하여 수행.
BO_lgb.maximize(init_points=5, n_iter=10)
BO_lgb.max # 가장 최적의 하이퍼 파라미터 값을 가짐
출처 https://sonsnotation.blogspot.com/2020/11/12-bayesian-optimization.html https://github.com/fmfn/BayesianOptimization